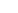 Menu
Menu
Microsoft Dynamics 365 / Power Platform - page 3
Nov 2, 2016 - Pointing Your New Build Definition to a Different Branch
Filed under: #daxmusings #bizappsThis will be quick, I promise! Many people ask about branching and I promise some day I’ll revisit my “how we do development” article to reflect my personal opinions on simple branch setups for AX7/Dynamics 365 for Operations (we really need a shorter conversational name, but I’ll wait for the community to find something good and stick with SEO for now :-)
But, skipping the branching discussion for second, if you do use branches, how do you deal with builds? Well, that is really easy. You clone the existing definition, change the repository mapping and change the build task to point to the correct folder’s project file!
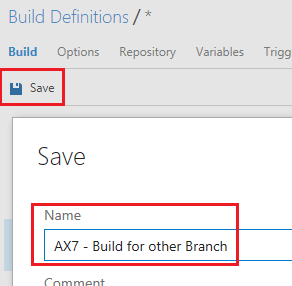
Step 1: Clone the original build definition Click on the ellipsis (…) next to the build definition’s name in your build definition list, and click “Clone”.
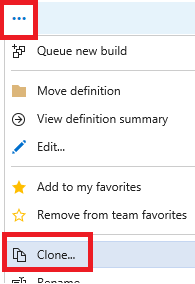
Step 2: Change the repository mapping Cloning should copy the original definition and open it for editing. On the “Repository” tab, change the “Mappings” to point to your new Server Path for your branch. (this screenshot shows trunk/main still, change that to what you need).
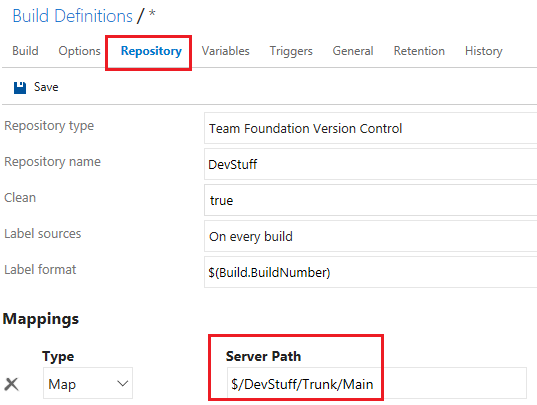
Step 3: Change the project file location in the build tasks On the “Build” tab, select the “Build the solution” task and edit the project location. I advise to use the browse feature by clicking the ellipsis, to make sure you don’t mistype.
Step 4: Save & Run! That’s it! Make sure to save your changes, and on the save dialog give the new build definition a proper name. At this point you can create multiple build definitions for the branches. You can play with setting for example any dev branches as gated builds or nightly builds, change the build numbering to clearly distinguish between builds from different branches, etc. Go wild!
Cool. This must be the shortest post I’ve done in years! Happy building!
Oct 4, 2016 - The Overall Concept of Extensions in AX 7
Filed under: #daxmusings #bizappsUnfortunately Dynamics AX 2012 also introduced a concept of extensions, which I blogged about here, but it’s not quite the same thing. The extensions from AX 2012 have sort of transformed in what is now known as plug-ins. More on that in a future article.
Although I’m enthusiastic about extensions, and many people share my enthusiasm, I’ve consciously (and with a hard-to-gather dose of restraint) decided to blog about the paradigms around packages and the package split first. The reason is to frame extensions properly. Extensions are a way to add features and functionality to the existing application, yes, but they are more than just a new technology feature in AX. They are an ENABLER to make the new paradigms and the strategy around packages successful. Developers should strive to use extensions to drive a move towards APIs and packages, not just to avoid over-layering (although the two are closely related). The goal is to move into independent loosely-coupled packages, and to attain that goal over-layering should be avoided, yes.
So what are extensions? If you think about customizations and Partner and ISV solutions, for the most part they add features and functionality to the existing application. I.e. they extend it. For this to succeed, they must be able to add fields to existing tables, execute code when certain things in the standard application happen, etc. Traditionally, this is done by over-layering the standard objects and code, and adding any needed new features. With extensions, the goal is to allow adding these additional features without over-layering, and even extending them from different packages. This seems fairly straight-forward from a metadata perspective. Indeed, adding a field to a table was already very granular by layer and model in AX 2012. And adding a form to a control was possible at runtime using personalizations. From a code perspective, however, things seem much harder. In AX 2012, eventing was introduced. One could add a pre- or post-handler to a method without technically over-layering the method. However, if for example a table didn’t define a modifiedfield or update method one had to over-layer the table first to add the method, then add a handler to it. This obviously defeats the purpose entirely. And even when one added a handler or even an entirely new method to an existing class, you were technically still over-layering the class itself in a way.
So yes, beyond the expected tooling around adding fields to tables, controls to forms, etc., there are concepts to facilitate code extensions as well. First and foremost, events are everywhere. Although the traditional way of overriding a base method on a table or form or form control still is possible, most of those methods which were semi-events, are now ACTUAL events. A table for example has an OnUpdating and OnUpdated event, which allows you to subscribe to a pre- and post-update event without creating any methods on the table itself. A form button control actually has events for a click event, etc. These system-defined events are already numerous, and will be expanded further in future releases as the needs become clear. So how about classes? Well, here there is already a difference between the original released version from February and the “May Update” (also known as “platform update 1”). Both versions have the concept of extension methods, which pretty much mimic the C# behavior of extension methods. With the May Update a new feature was introduced that allows a more broader concept of extending where the extending class can actually define new instance member variables it can use. Note that in both cases the extension cannot access private or protected member variables - it adheres to scoping rules, and makes sense when thought of in the API-sense.
Let’s leave this wall of text for what it is, and start looking at actual examples of extensions in the upcoming blog posts.
Sep 29, 2016 - The Package Split
Filed under: #daxmusings #bizappsAfter reviewing the new paradigms in AX 7, it’s time to put these paradigms to practice and review the current and future state of the Dynamics AX application code. To recap, a package corresponds to its own mini-modelstore, with its own layers and models. Each package roughly translates to a .NET assembly, meaning it’s a unit of compilation. It also means one cannot over-layer from one package to another. Packages can “reference” each other, exactly like other .NET assemblies can reference each other. This is needed so one package can use features of another. This concept is being put to use in the standard application code, and the ongoing effort to accomplish this split-up is commonly referred to as the “package split”.
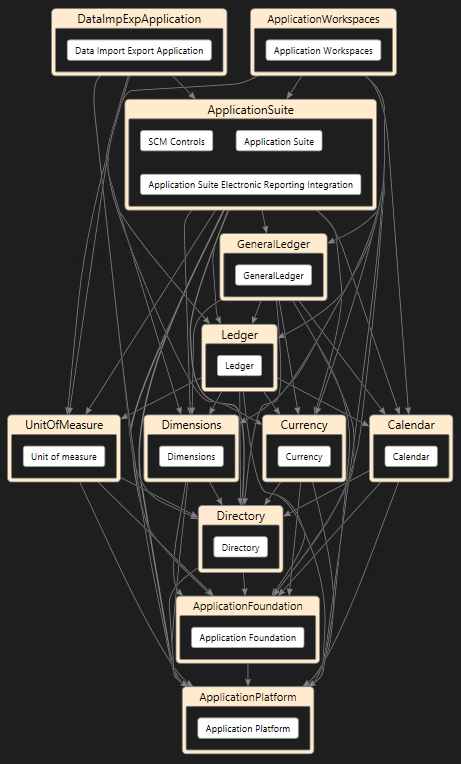
Initially, the package split can be thought of in three main areas: the platform, the foundation, and the application. The platform is all the essential AX platform pieces that are not in the kernel but in X++, yet they are essential to the AX platform. Things like the users tables and the form to create and maintain those users. The foundation contains basic features that most of the application code will depend on. Things like the number sequence functionality. Finally, the application itself, which is all the business logic. Although you can think of those big three, the “application suite” as the package is called is slowly being split up further. You’ll see packages like “general ledger” and “dimensions” that have been split off from the application suite. In a sense they sit in between the foundation and the application suite, because they are application logic but they are shared between different modules and functionalities.
So what is the use of having these separate packages? In a nutshell, it’s all about maintainability and serviceability. As we discussed in the paradigm articles, having code in packages as opposed to a huge monolithic code base allows for faster compiles (since you’re only compiling the code for your package / .NET assembly). Whereas AX 2012 and before would either require you to compile the whole application (or, in case you’re into bad practices, take the risk of importing an XPO and just compiling forward or something), the new AX decreases the compile and deployment time needed by splitting up the code into packages (even though the compiler is already significantly faster than previous versions thanks to a rewrite). This has clear advantages during development (for example, being able to do continuous integration or gated check-ins, which is very difficult if your build takes 30 minutes or more. But it also has advantages for deployment, and testing. It’s clear that a split in smaller packages means smaller and faster compiles and smaller and faster deployments. But considering that you cannot over-layer from one package to another and packages reference each other as .NET assemblies (DLLs), it means you can replace and update packages independently, as long as the API to its functionality doesn’t change. Yes, I said API :-)
If you look at a dependency graph of the packages in the new AX, you’ll find that the packages at the bottom are more like APIs. An API for number sequences, and API for dimensions, etc. At the top end, you’ll have the ultimate consumer of those APIs. The application suite and other packages, providing the end-user functionality of the business logic. If a hotfix is needed on the number sequence functionality, the foundation package can be hotfixed and replaced without requiring a re-compile or re-deployment of the application suite - provided none of its APIs changed (which wouldn’t happen for a hotfix of course). It also wouldn’t require any code upgrade, assuming there are no over-layering models in the foundation package. And that is the gotcha…
Below a “simplified” view of the standard package hierarchy in AX7. Some packages were left out to show the idea. Since packages “reference” each other like normal .NET assemblies, the references are not transitive and usually the package at a “higher” layer needs to reference some of the lower layer packages as well. But clearly, everything references platform, some reference foundation, and it goes up from there.
So, to avoid over-layering and also keep one’s code in a separate package to facilitate quick compiles and easy deployments of custom code, what is a X++ developer to do? That, my friends, is where extensions come into play. To be continued…
May 25, 2016 - Design-Compile-Run Part4: Paradigms in AX7
Filed under: #daxmusings #bizappsFor the fourth and final part of this design, compile, run series we’ll review the structure of the AX7 model store in light of what we’ve reviewed in Part 3 (and contrast it to AX 2012 as explained in Part 1 and Part 2). This will be a lengthy article, hang on!
We’ve reviewed the tooling for each phase (design-time, compile-time and run-time) and even discussed the file formats for each phase in the previous article (Part 3). We also discussed the fact that the separation of design-time and run-time is strict in AX7, meaning your code only exists at design time. Since you can only execute one version of a binary at the run-time, at compile-time the compiler will “flatten” all your models and layers and come up with the final version of the code across models and layers and compile that into your binary. This implies that layers and models are a design-time concept only! The run-time has no notion of models or layers (similar to previous versions, really, but as discussed in previous posts the line was slightly blurry then). So in part 3 we talked about file formats and discussed that each object is an XML file on disk. What used to be the “model store” is now really a folder on your development machine, containing a folders and files structure. The lowest/deepest level folder is for models, and inside a model folder you will find sub-folders that resemble the old-school AOT tree nodes. Essentially, each model folder contains a sub-folder for each type of object. You’ll find the usual suspects (folders for AxClass, AxEnum, AxForm, AxMenuItemDisplay, etc.) but also new ones for AX7 (AxDataEntityView, AxFormExtension - we’ll touch upon the new “Ax<*>Extension” objects later on). Now, for most of these you’ll find that the object type’s folder has ANOTHER sub-folder called “Delta”…
Let’s think back to over-layering and granularity in AX2012 as discussed in Part 1. We talked about certain sub-components (or essentially AOT tree nodes) of an object allowing over-layering, and sometimes not allowing it - meaning the whole object would be copied into your higher layer. The level of detailed over-layering is what we called the “granularity” of an object. This depended on the type of object. In AX7, each and every single object is granular down to the PROPERTY. That’s right. If you change the label of an EDT - only that label property is over-layered, not the whole EDT. So, you can happily change the label in one layer, and the helptext in another. And the string size in yet another layer. But wait - there’s more! In addition to ONLY storing the property you’ve changed by over-layering, it also stores the original value of what you’ve changed. The reason this is important will be clear to anyone who’s had to deal with upgrades or updates or any kind… When comparing a higher and lower layer version of an object and a difference is found, the question usually becomes: is that lower layer version the one I changed, or did that just get changed in the update and do I need to re-evaluate my custom version? It becomes a bigger issue with X++ code - a whole method is over-layered and you notice a line of code that changed… but did you make that change originally? Or is the lower layer code changed and your code just has the old standard code (and so you need to merge it)? Usually the only way to tell is go back to an instance of the old version, see what explicit change you made, then decide if you need to merge anything. It can be tedious process depending on the type of customizations you have done, and it gets very difficult to automate any of this. So now, in AX7, your over-layered version (i.e. the delta XML file) contains the original code or property value you’ve changed. This way, you have an automatic three-way compare possibility: 1) the new lower-layer code; 2) the old lower-layer code you changed and 3) your customized code. This makes it a lot easier to compare and merge, and it is also the back bone of the automated tooling that LCS provides to upgrade and update your code.
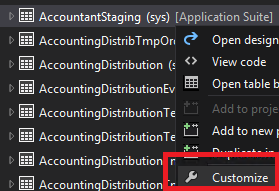
So what does this look like? I created a new model from the Dynamics AX menu, and selected to add it to an existing package called “application suite” (more on this later). I opted to created a new project for this model. Once created, I open the Application Explorer (the new AOT) and the first Data Model / Tables object I see that is in Application Suite is called “AccountStaging”. I right-click the table and select “Customize”. This adds the table to my project with a [c] next to its name.
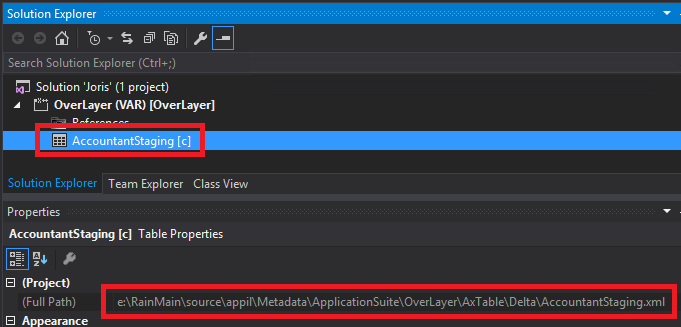
Right-click on the table and select “Properties”. Scroll all the way up in the properties and you’ll notice the full path to the XML file. Let’s open that XML file in notepad. Since I actually haven’t changed anything on the table yet, the file is virtually empty. Here’s what I have:<pre><?xml version="1.0" encoding="utf-8"?>
<AxTableDelta xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<Conflicts />
<DeltaName>AccountantStaging</DeltaName>
</AxTableDelta>
</pre>Now, double click the table or right-click and select “Open”. In the properties of the table (in the designer view, right-click, select Properties) change the Label to “DAX Musings rules” (or if you disagree, feel free to put some other text - it won’t mess up the rest of this article’s demos) and save. Let’s now open that XML file again.<pre><?xml version="1.0" encoding="utf-8"?>
<AxTableDelta xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<PathElement>
<Path>AccountantStaging</Path>
</PathElement>
<Conflicts />
<DeltaName>AccountantStaging</DeltaName>
<Label>
<PathElement>
<Path>Label</Path>
</PathElement>
<Original>@GLS4170035</Original>
<Yours>DAX Musings rules</Yours>
</Label>
</AxTableDelta>
</pre>As you can see, the only thing added to this delta file is the label property, and it contains the original value and my new value (“Original” and “Yours”). How this is used and what conflicts are related to this, I’ll cover in another article.
Ok, so we have a model with an over-layered object… But since we’re now storing over-layering as granular as the property, what does this mean for having multiple models in the same layer? Well, yes the granularity down to properties will avoid a lot of model conflicts, but in AX7 it doesn’t matter… because models over-layer each other! That’s right, models are essentially a sort of sub-layering system. This is certainly food for thought and content for an article, but for now - consider models sub-layers and essentially there’s an ordering of models to know which one is higher than which other one within a given layer.
Going up the folder path from the model, you get up to the package folder. Models exist inside a package - but what does that mean? Going back to the 2012 paradigms, consider the package as sort of a model store in and of itself. A package has layers and models, and when compiling a package translates one to one into a .NET assembly (.DLL). So when compiling a package, as explained, the compiler will “flatten” all the layers and models into the final version of the source code including over-layered code, and compile the package into an assembly. So, when I mentioned in the previous article that you always have to compile all the code, you truly only have to compile the whole code of the package you’re working in…
So, there are a LOT of consequences now that we know how packages and models work…
1) If a package is compiled by itself, and the compiler flattens the layers… that means over-layering can only be done within one package! You cannot over-layer something from another package (consider what we talked about how the compiler does its work…)
2) If a package is a DLL, that means if code is split up in multiple packages, you can compile them individually (reducing needed compile time), deploy/service them individually, etc.
3) If a package is a DLL, then using objects from another package/dll requires you to make a “reference” like you would with any other assembly DLLs.
<pause added for dramatic effect>
Thinking of those 3 consequences, the first one seems the more immediate significant difference compared to AX 2012 and before… if we can’t over-layer from another package, what’s the point of having separate packages entirely? The benefits like faster compiles and easier servicing and deployment make sense, but how does one customize then? For this purpose, AX7 features a new development paradigm called “extensions”. The many features that make up extensions essentially allow you to “add” (i.e. extend) things to the standard application. Adding menu items to menus, controls to forms, fields to tables, etc.
So for all the talk about over-layering and delta files and three-way compare&merge upgrades, extensions is where our focus as developers should be! :-)
May 5, 2016 - Design-Compile-Run Part3: Design, Compile, Run in AX7
Filed under: #daxmusings #bizappsThis is Part 3 in my design, compile, run series. Please first read Part 1 about paradigms, and especially Part 2 on design, compile, run in AX 2012.
In part 2 I explained the design time, compile time and run time differences in AX2012. However subtle and vague they may be, they are there. We can (mostly) choose to ignore them, if we wish, but ultimately that is how the system works. In the new Dynamics AX (AX7), these three distinct phases are hard facts that you cannot work around. There is a design time in Visual Studio where you create your code and your metadata. There’s a compile time where that code and metadata is taken and compiled into DLLs. And then there is a run time that can run those DLLs. And although the compile time is integrated into Visual Studio (the design time), it’s essentially a command-line utility that Visual Studio calls to invoke that compile time. Let’s look at what this looks like.
I’ll re-use the graphics from the previous post, in reverse order, to build back up to the paradigms in the next post. First, let’s look at the tools we use in AX 7. As you probably know by now, AX 7 no longer has a client. Everything runs server-side, and there is some browser code (arguably that could be considered a type of client) that displays everything from the server. So the AX 2012 client which hosted both the design time, compile time and run time is entirely gone, so there is no tool left that spans all three phases.
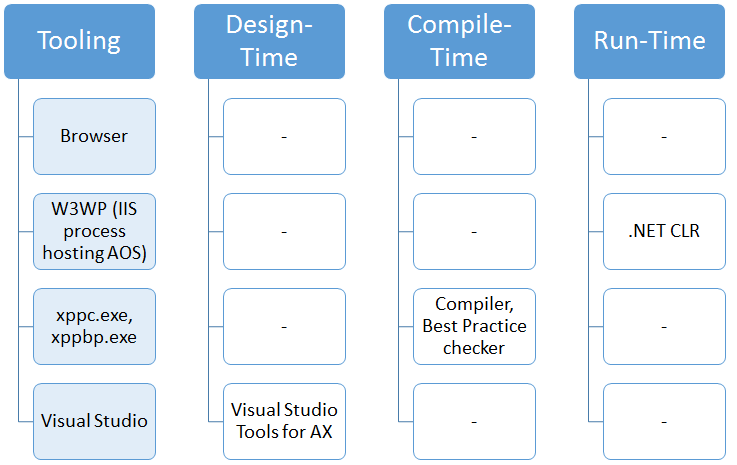
Immediately noticable is that each tool handles a specific phase, there is no overlap anywhere. There’s design-time tools (Visual Studio), compile-time tools (xpp compiler - xppc) and the .NET run-time running with the AOS kernel in IIS. Note also that there is no X++ interpreter anymore. X++ is now a 100% managed language running in the .NET CLR. The compiler is now rewritten entirely and compiles directly to .NET assemblies (and is scalable… give it more memory and more CPU and it will go faster). Of course, this has some implications to the traditional way I described in the previous post. For one, you always have to compile everything (although there’s good news here, we’ll describe what “everything” really means in the next post). If you have a compile error, you don’t have anything to run. This also means you actually have compiled binaries to deploy. The run-time can’t do anything with code, it can only run binaries. Which means for deployment purposes, you’re deploying binaries not source code. So no merging and all that because that is a design-time task.
Next, let’s look at the next slide of what “file formats” exist in each phase.
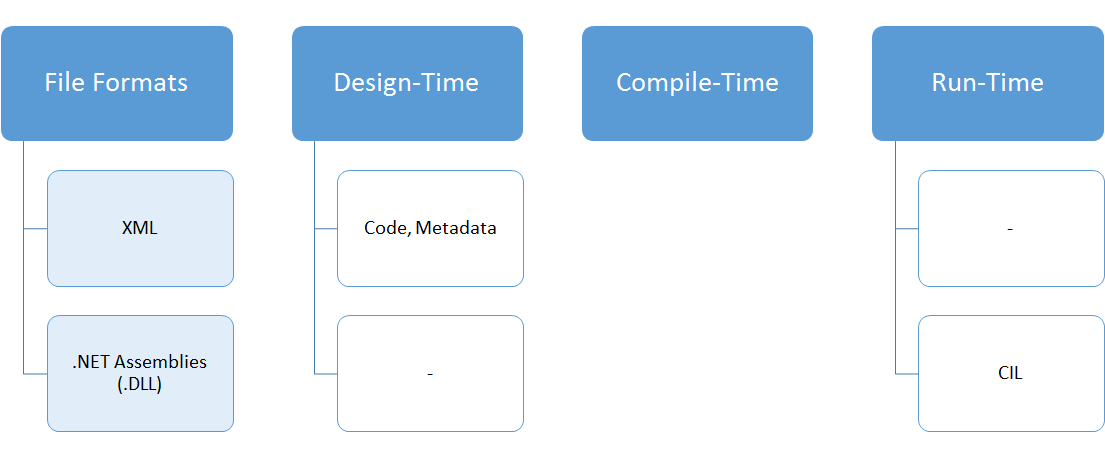
So, yes, XPOs are finally gone! And make no mistake, the XML files are not just a replacement - they ARE your code files now. Since design-time is separated from run-time, you don’t “import” your code into a server. The code is a bunch of (XML) files on disk. The next question that comes up a lot is then - but how do I run the code in Visual Studio? Well, just like you would be creating an ASP.NET app or such, Visual Studio will run the compiler for you, then copy the binaries into a local IIS server, and start the IIS process. Visual Studio doesn’t run your code, after compiling it deploys the binaries and then opens a browser - exactly like a C# ASP.NET project. That means when you edit code and or change forms from within Visual Studio, you are actually editing XML files. This has a few important implications!
1) You cannot “share” a development box for several reasons. If two developers are editing the same file at the same time, the last one that saves wins and overwrites. Think of editing a .TXT file in Notepad. If two people open the same file at the same time, the first one makes a change and saves. The second (who doesn’t have the first one’s changes) makes a different change and saves. Essentially, only the second person’s changes end up in the file. The other reason is similar to AX 2012 - if someone has work in progress you could have compile errors, which now in AX7 entirely prevent you from generating the assembly DLLs for the runtime. 2) Since all code is files, and we are working inside Visual Studio, source control is a breeze! Where in previous releases of AX there was always an export to XPO and then check into source control (essentially a two-step process in different formats), you are now editing EXACTLY what you will check into source control. More on this in the next post when we talk about the new paradigms. 3) Some “automatic” relationships that existed when the AOT was part of the runtime (let’s say, renaming a field) no longer resolve. If you rename a field, you’ll have to get the list of references (or do a compile to get the errors) and fix the artifacts and their files (for example, form controls etc.). This is a good thing: in AX 2012 this could cause issues when using source control - a field rename would fix some things automatically in your AOT, but wouldn’t check-out and re-export the XPOs of those “fixed” artifacts, probably causing issues for other developers, builds, etc.
Of course, these are the file formats for the artifacts that the phases use. But now we have another new concept - file formats for DEPLOYING those artifacts.
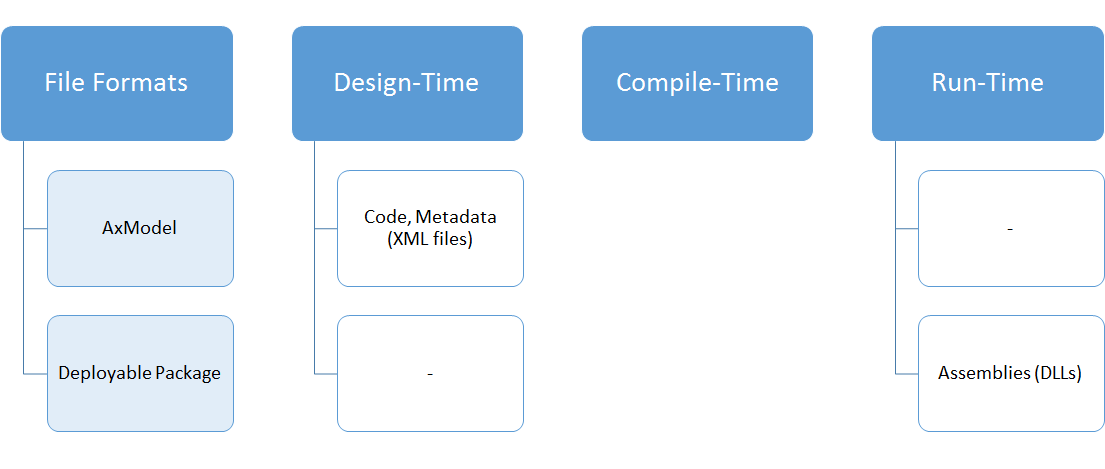
The concept of an AxModel still exists, and it’s now essentially just a zip file with all your model’s XML files in it (plus the model manifest, now called the “descriptor file”). AxModels are a format to distribute code around, but mostly between different development parties (such as an ISV, a Partner and a Customer). To keep source code in sync between developer’s machines at the same company, we use what we everyone else is using: source control. Although some new LCS features require you to use VSTS (Visual Studio Team Services) with TFVC (Team Foundation Version Control), for source control purposes only you can use whatever Visual Studio or its plugins support. You can use VSTS with git, you could use GitHub, etc. Note that VSTS with TFVC is currently required for project management and code upgrade features - support for other source control systems is being evaluated and may get added in later versions. The concept of the model store needs some rethinking, we’ll discuss that in the next post. But as we discussed here, the run-time just needs the DLLs of your custom code. We don’t want you to just copy DLL files around, so there’s a concept of a “deployable package” which is essentially a collection of one or more DLL files with scripts to deploy it. Today there are some manual steps to deploy that deployable package, but automation for this is just around the corner. So, when deploying code to a test environment or production environment, the deployable package is the vehicle to distribute your compiled assemblies.
Both the model file and the deployable package can be outputs of your automated builds. We’ll discuss builds and automation some other time.
Next post, let’s put these tools and file formats in perspective and review the paradigms and architecture in AX 7.
May 4, 2016 - Design-Compile-Run Part2: Design, Compile, Run in AX 2012
Filed under: #daxmusings #bizappsIn Part 2 of this design, compile, run series we’ll look what design, compile, run actually means in AX 2012. If you haven’t read Part 1 about the paradigms in AX 2012, please do.
We’ve looked at layers and models in Part 1 of this blog post series. In versions prior to AX 2012, these layers were stored in a physical file (AOD file) - each layer had one file on disk. In AX 2012, this changed into a Model Store database - containing all the layer and model’s code, metadata as well as all compiled p-code and generated CIL binaries. Let’s look at what these concepts really mean and represent.
First consider the metadata and code. When we say metadata we are talking about the form definitions, table details like relationships, indexes, schema representation etc. They are not “code” per se but represent an artifact in a meaningful way that is needed during development and parts of running the application, and some of it is used by the compiler as well. The second thing the model store contains is the p-code and generated CIL. This is the binary form of the compiled code and metadata that is used to actually run the application. X++ originally (in AX2012 and before) is an interpreted language, and the p-code represents an easy way to run the code. The advantage of this is that parts of the code can be adjusted and only those parts have to be recompiled for the runtime to work. The disadvantage is that errors can easily occur at runtime when individual parts are changed without recompiling everything else in the system that may have a dependency on it. Additionally, since it’s p-code that is executed by an interpreter at runtime, the performance of the execution can’t match that of a properly compiled binary. The introduction of CIL in AX2012 changed this story slightly. After the p-code is compiled, an extra process needs to be run that will translate the p-code into .NET assemblies. This step may fail if, as explained before, the application has errors due to individual parts having been changed without recompiling and resolving all consequential errors. The advantage is of course that X++ code can be run inside the .NET CLR. The disadvantage is it conflicts with the traditional change&save model of X++ since this can cause issues. Additionally, if CIL generation runs into errors the application is potentially in an unknown state. It is entirely possible to have the CIL assemblies be in an “old” state (since new compile failed) while the X++ p-code has the latest changes. Essentially that means you could be executing different versions of the code whether you are running X++ interpreted or in the CLR if your development and deployment processes aren’t solid.
Since traditional development for Dynamics AX occurs inside the AX client, the underlying structure and process is not very visible, which could lead to broken deployment processes. It’s important to understand these details to have a solid AX 2012 development and deployment process. It will also make the AX7 processes clearer. Based on the above information, let’s make the following three buckets: design-time, compile-time and run-time. Within the model store, there are both design-time artifacts and run-time artifacts. Note that the run-time does NOT have models or layers.
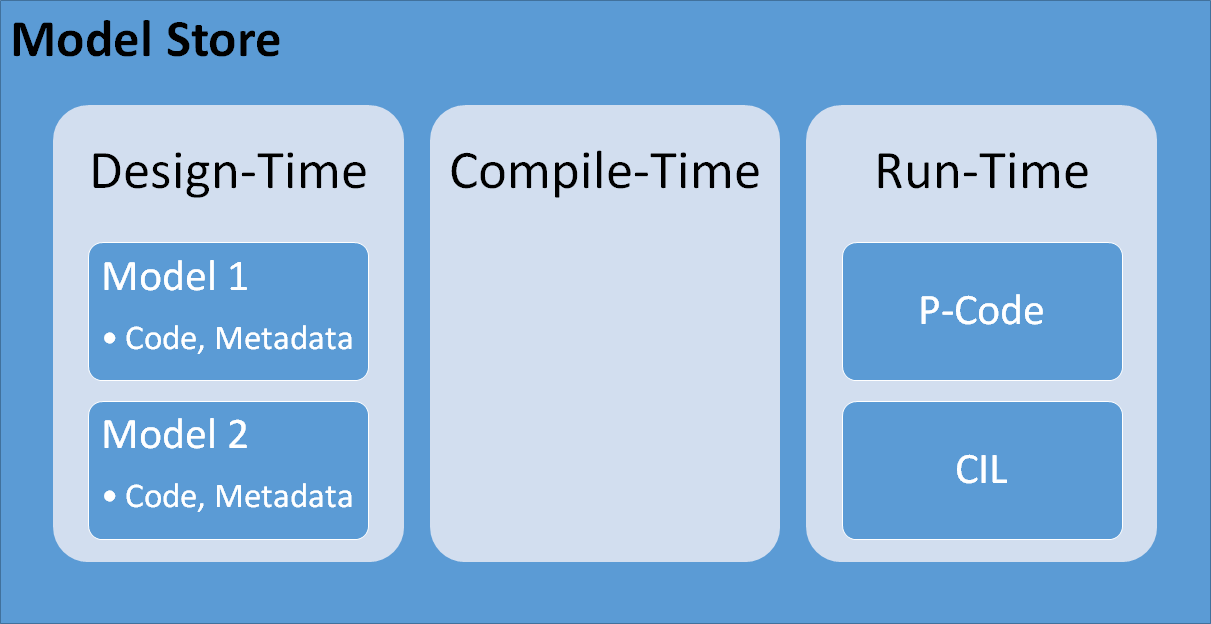
Why? Well, at the time of compilation the compiler will take the top-most version of each object artifact (think “granularity” as explained in part 1) and compile that into binary p-code (which then is used to generate CIL). That makes sense: first, you can only execute one version of the code so why have binary versions of each layer or model? Second, one piece of code may reference another piece of code - and each may exist in different layers, so the compiler needs to make a decision on what code to compile against. So all in all, the compiler will “flatten” all the code and metadata into one version of the truth, and convert that into binaries.
Now that we understand the underlying distinction between design, compile and run-time and what artifacts each contains, let’s review what tools are used for each.
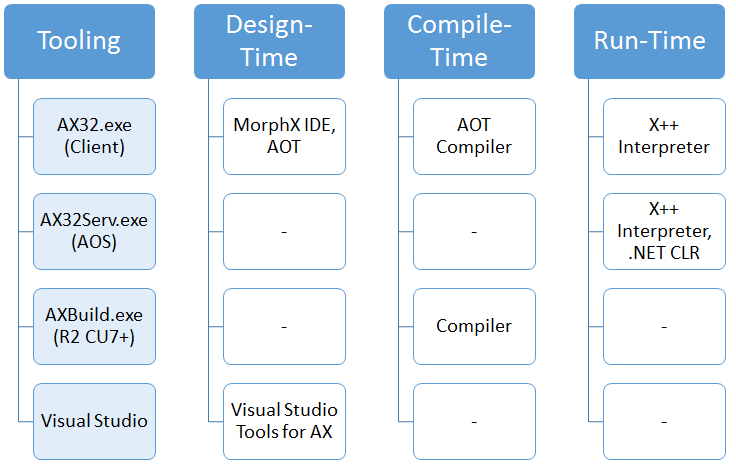
I realize this is a simplification, there are other runtimes like BC.net and SharePoint Enterprise Portal, but in general times this a good representation for the sake of this discussion.
- The AX32 client is the most comprehensive. It contains design-time tools, compile tools and an X++ interpreter to run the p-code. Note that it doesn’t have the .NET CLR so it cannot run the X++ CIL.
- The AX32Server AOS is mostly a run-time which can run both the X++ interpreter for p-code as well as the .NET CLR to run X++ CIL. Note that in theory this has a server-side compiler in it that is used by the AxBuild process but one would never explicitly use it.
- The AxBuild process was introduced in AX 2012 R2 CU7 and is available ever since. It’s strictly to compile, and although it technically starts the AX32Serv executable to compile, we’ll consider this the compiler.
- I also included Visual Studio as a design-time tool, although from an X++ point of view there isn’t much functionality and its mostly used for reports or non-X++ code (C# etc).
Finally, although all of this is stored in the model store, there are different file representations of different artifacts. These are file formats and vehicles to transport these artifacts (i.e. deployment artifacts).
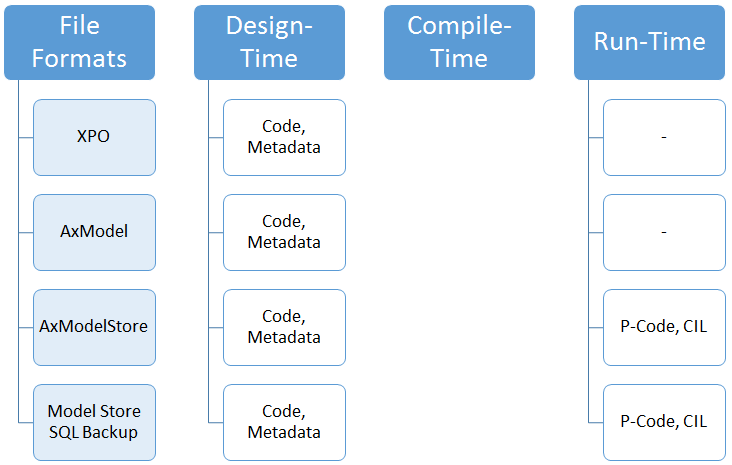
First is the traditional XPO file. It’s essentially the closest to a “code file” you can get with X++, it represents an object and its metadata and source code. Although one could have an XPO containing all customizations to an environment, it’s no longer recommended as a vehicle of deployment but treated for what it should be: a code file. Meaning it’s good to share bits and pieces of code among developers, as well as source controlling code artifacts. Next is the AxModel file. This is essentially a collection of source code, typically representing a full solution of a responsible party. For example an AX customer’s custom code, an ISV’s product, a VAR’s add-on, etc. Note from the diagram you see the AxModel file, although a binary format (actually it’s a .NET assembly), is still just code and metadata. This means just like the XPO, installing it on an environment only gives you the code and you should still compile everything. Finally the model store, which contains all code, metadata, p-code and CIL can be exported as an AxModelStore file, or a SQL backup can be taken to move it. Since this contains everything, there is no need to recompile anything when moved. The model store file or model store database backup is the closest we get in Dynamics AX to moving a compiled binary. As I keep reminding people I meet that have questions around all of this, I like the analogy of a program or windows update. When there is an update, does the software vendor send you some C++ files (i.e. XPO)? Or is it more a Linux-like source code package that can be compiled (i.e. axmodel)? Or do they send you a new version of the DLL (i.e. model store)?
Next part, we’ll transition into AX7 based on what we reviewed in this article.
May 2, 2016 - Design-Compile-Run Part1: 2012 Paradigms
Filed under: #daxmusings #bizappsIf you haven’t already, please read the intro first.
In this first post, we’ll discuss development paradigms such as modelstore, layers, models, AOT artifacts and more. If you’re reading this chances are you know most of these details, but I encourage you to read through this as the details are important to understand the changes being made in the new Dynamics AX (AX7).
To roll into this series, we’ll discuss some typical paradigms. Dynamics AX has a system of models and layers (layers have always been there, models were introduced in AX 2012). The layers allow responsible parties to entirely separate their original source code and design artifacts, while allowing the next party (in the chain of vendor to customer) to customize all the code delivered by the previous parties. The number of layers is fixed (although the amount of layers and their names has changed over different versions of AX), and are named after the typical parties involved in an implementation. Within each layer, any number of models can be created. There is always a default model in each layer (called “XYZ model” with XYZ being the name of the layer). Let’s look at what these layers and models represent and how they work.
Assume the case of a table delivered by an ISV, in the ISV layer. It contains one key field, a method, and it overrides the validateWrite() system method. The partner implementing this solution has made some more industry-specific changes, adding a field and extra validations in the validateWrite() method. To do so, they over-layered the table in the VAR layer. Additionally, the customer decides to change the labels on the ISV and the VAR field, as well as add a method.
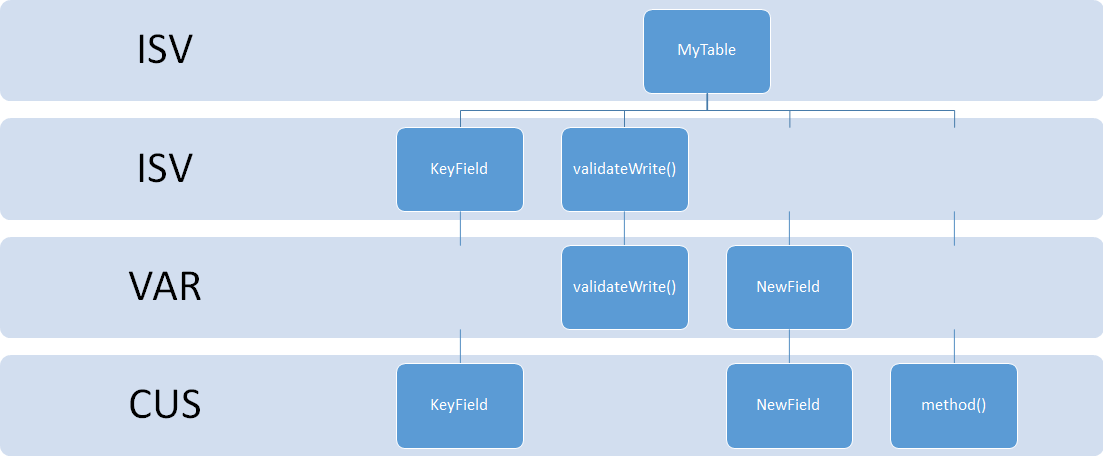
Essentially, the table itself is now created in ISV, but different parts of it exist in different layers. Now, imagine the customer hiring another third party to make some more changes, who implement those changes in their own model in the VAR layer. Now the table also exists in multiple models in the VAR layer.
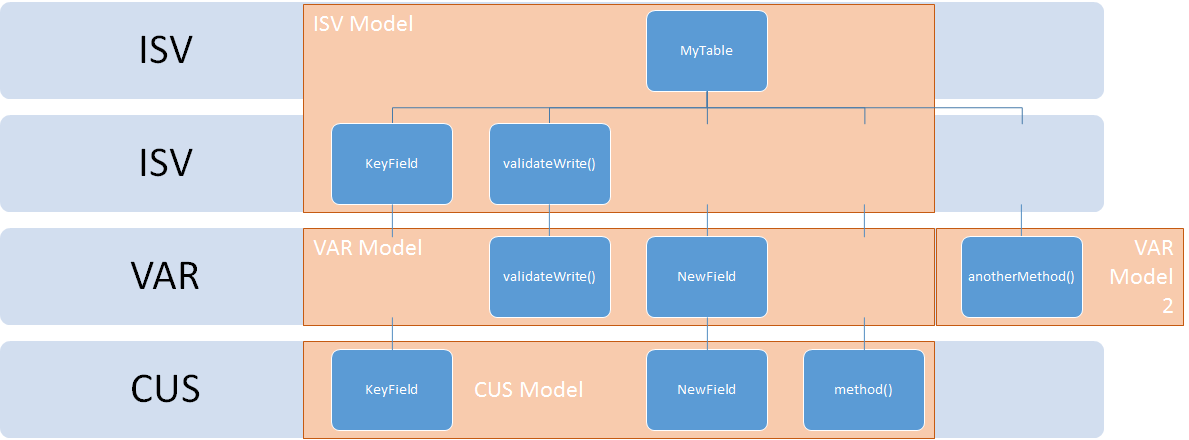
Looking at the customizations that were made, there are two distinctions to make. Some elements of the table are CHANGED in a particular layer, other parts are completely NEW. As we’ll see in later posts, in the new Dynamics AX (AX7) the terminology for this is a customization (change) versus an extension (new). When a change is made to an existing element, that element is ‘copied’ from the lower layer (say, ISV) into the layer it is being customized (say, VAR). At this point, the element exists in both layers, but the compiler and runtime of AX will always only use the higher layer version of the element. The name ‘element’ is quite ambiguous here. In our table example, fields and methods are definitely elements that can individually be added or changed (over-layered) in different layers or models. However, there are certain sub-elements that CANNOT be individually over-layered. For example on tables an index is an element that can be individually over-layered, but individual fields in the index are not. The index as a whole will always be copied into the higher layer when customizing. Another example is the datasources node on a form. As soon as you add a method to a datasource or add a new datasource, the whole datasources node is copied into your layer including all the other datasources, methods, fields, etc. Other elements, like Menus for example, do not allow any sub-elements to be over-layered and are always entirely copied. The concept of what element level objects can be over-layered is often referred to as the granularity of objects. Some objects are entirely granular (for example classes, since both the class itself, its methods, and event subscriptions can all exist in different layers and models) and some objects aren’t granular beyond the parent level (like menus). This of course has a major impact on upgrades of code. If the lower layer is updated, the higher layer needs to compare any over-layered elements. So obviously, the less granular an object is, the more work an upgrade will take. Another effect of the granularity has to do with models within a layer. Models have the limitation that within one layer, an element can only exist in 1 model. So the more granular an object’s elements are, the more it can be customized in different models within one layer. In our diagram’s example, if tables were only granular to the table level itself, the VAR layer couldn’t have had a new model that adds another method. With the granularity of tables as they are, a method or field can be added in the same layer in a different model. However, the new VAR model cannot also add a customization to validateWrite(), since that method in the VAR layer already exists in the other VAR model…
Tip: to see granularity of objects, go to your user options in Tool > Options and on the Development tab under “Application object tree” set layer to “show all layers” and model to “show on all elements”. Once those options are on, you will see the layer and model listed for each element in the AOT. If an AOT does not show a layer/model, it means it’s not granular and you have to look at its parent. For example on forms, note how all the controls are granular (they list a layer and model), but individual datasources do not, only the datasources node as a whole does.
In part2, we’ll review the “design, compile, run” principles in AX 2012.
Apr 28, 2016 - Design-Compile-Run Intro
Filed under: #daxmusings #bizappsOver the last few years I’ve talked a lot (both online and offline) about how we should all strive to put software engineering practices back into AX. What I mean by that is that we’ve become lazy in how we do and manage our development, because AX has certain features that allows us to do just that. But with the product growing bigger, the features becoming more advanced and the projects getting bigger and more complex, the need to go back to those good practices has grown as well. As a result, the demand for Version Control and other development best practices for AX has become bigger. With the release of “the new” Microsoft Dynamics AX, some major shifts in this regard are happening. All for the better, but for some people this may represent a departure of some AX-specific practices.
Starting next week, I will be posting this blog post series “Design - Compile - Run” as a guide into paradigms and their meanings, starting with AX 2012 and leading into the new Microsoft Dynamics AX. I hope this will help serve as a guide to get your AX 2012 development processes in line and ready for the new AX. Discussing some details of designing, compiling and running AX is valuable information and will help you understand the new AX better.
Part 1: AX 2012 Paradigms Part 2: Design, Compile, Run in AX 2012 — Part 3: Design, Compile, Run in the new AX Part 4: the new AX Paradigms
Mar 14, 2016 - (The New) Dynamics AX - Content
Filed under: #daxmusings #bizappsIf you haven’t heard, the new version of Dynamics AX is out and available. Lots has changed and there’s plenty to learn. Beyond the blogosphere there’s some official places to find out all about the new features. We held our technical conference about a month ago, and for partners and customers that content is now being made available online.
So here’s some links you want to bookmark:
Technical Conference 2016 Session Recordings (partners) Technical Conference 2016 Content (customers & partners) Dynamics AX Wiki (Official help site, public) - expect lots of updates here (what did you expect, it’s a wiki!)
Sep 18, 2015 - General Update
Filed under: #daxmusings #bizappsIn case you hadn’t noticed… I haven’t posted in a while. For those of you who are connected to me in various ways, you have probably also noticed I had a job change and now work for Microsoft Dynamics AX R&D as a senior solution architect.
Essentially, in my new job I will be able to continue blogging and speaking at conferences. In fact, I will be at the AXUG Summit in October and speaking there. This blog will remain my personal blog and the open source projects will be maintained as well (more on that coming soon). Of course as a personal blog nothing I say or post here is backed up by Microsoft (see disclaimer at the bottom of the pages).
Currently we are hard at work on AX7 and I can’t wait to start sharing and blogging about all the goodies for developers. But until then, it will probably be a bit quiet here (except for some planned improvements on the AX2012 build automation). Please connect with me on Twitter and stay in touch.
Blog Links

Blog Post Collections
- The LLM Blogs
- Dynamics 365 (AX7) Dev Resources
- Dynamics AX 2012 Dev Resources
- Dynamics AX 2012 ALM/TFS
Recent Posts
-
GPT4-o1 Test Results
Read more... -
Small Language Models
Read more... -
Orchestration and Function Calling
Read more... -
From Text Prediction to Action
Read more... -
The Killer App
Read more...