 Menu
Menu
All Blog Posts - page 7
May 1, 2013 - Mixing Dynamic and Static Queries with System Services in AX 2012
Filed under: #daxmusings #bizappsIn the “old” blog post about using WPF connected to the query service in AX, we talked about consuming a static query and displaying the data set in a WPF grid. The goal there was to be able to whip this up very quickly (10 minutes?!) and I think that worked pretty well. In this post I’d like to dig a bit deeper. I’ve received some emails and messages asking for examples on how to use the dynamic queries. Well, I will do you one better and show you how to use both interchangeably. We will get a static query from the AOT, change a few things on it, and then execute it. All with the standard system services!
So, we will first use the metadata service to retrieve the AOT query from AX. In this example, I will be using Visual Studio 2012, but you should be able to run through this using Visual Studio 2010 just fine. We start by creating a new Console Application project. Again, we’ll be focused on using the system services here, but feel free to use a WPF app instead of a console app (you can merge with my previous article for example). I’m in Visual Studio 2012 so I’m using .NET 4.5, but you can use .NET 4.0 or 3.5 as well.
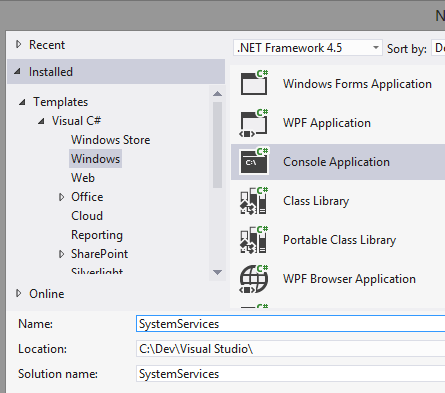
Next, right-click on the References node in your solution explorer and select Add Service Reference.
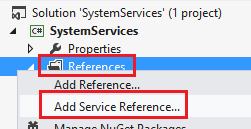
This will bring up a dialog where you can enter the URL of your Meta Data Service. Enter the URL and press the GO button. This will connect and grab the WSDL for the metadata service. Enter a namespace for the service reference proxies (I named it ‘AX’ - don’t add “MetaData” in the name, you’ll soon find out why). I also like to go into advanced and change the Collection Type to List. I love Linq (which also works on Arrays though) and lists are just nicer to work with I find. Click OK on the advanced dialog and OK on the service reference dialog to create the reference and proxies.
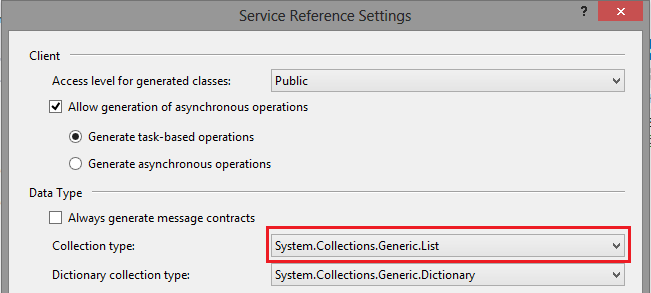
Ok, now we are ready to code! We’ll get metadata for a query (we’ll use the AOT query “CustTransOpen” as an example) and print the list of datasources in this query, and print how many field ranges each datasource has. This is just to make sure our code is working.
<pre>static AX.QueryMetadata GetQuery(string name)
{
AX.AxMetadataServiceClient metaDataClient = new AX.AxMetadataServiceClient();
List<string> queryNames = new List<string>();
queryNames.Add(name);
var queryMetaData = metaDataClient.GetQueryMetadataByName(queryNames);
if (queryMetaData != null && queryMetaData.Count() > 0)
return queryMetaData[0];
return null; }</pre></code> Very simple code, we create an instance of the AxMetadataServiceClient and call the GetQueryMetadataByName operation on it. Note that we have to convert our query's name string into a list of strings because we can fetch metadata for multiple queries at once. Similarly, we have to convert the results returned from a list back into 1 query metadata object (assuming we got one). We'll return null if we didn't get anything back. If you left the service reference Collection Type to Array, either change this code to create an array of strings for the query names instead of a List, or you can actually right-click the service reference, select "Configure Service Reference" and change the Collection Type to List at this point. We'll make a recursive method to traverse the datasources and their children, and print out the ranges each datasource has, like so: <code><pre>static void PrintDatasourceRanges(AX.QueryDataSourceMetadata datasource) {
Console.WriteLine(string.Format("{0} has {1} ranges", datasource.Name, datasource.Ranges.Count()));
foreach (var childDatasource in datasource.DataSources)
{
PrintDatasourceRanges(childDatasource);
} }</pre></code> I'm using a console application so I'm using Console.WriteLine, and I have a Main method for the rest of my code. If you're doing a WPF app, you may want to consider outputting to a textbox, and adding the following code somewhere it's relevant to you, for example under the clicked event of a button. Here we call our GetQuery method, and then call the PrintDatasourceRanges for each datasource.
<pre>static void Main(string[] args)
{
AX.QueryMetadata query = GetQuery("CustTransOpen");
if (query != null)
{
foreach (var datasource in query.DataSources)
{
PrintDatasourceRanges(datasource);
}
}
Console.ReadLine(); }</pre></code> Note that we have a Console.ReadLine at the end, which will prevent the Console app to close until I press the ENTER key. When we run this project, here's the output:
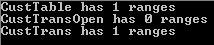
Ok, so we’re getting the query’s metadata. Note that the classes used here (QueryMetadata, QueryMetadataRange etc) are the exact same classes the query service accepts. However, if we add a new service reference for the query service, AX will ask for a new namespace and not re-use the objects already created for the metadata service. If we give it a new namespace we can’t pass the query object received from the metadata back into the query service. Of course I wouldn’t bring this up if there wasn’t a solution! In your solution explorer, right-click on your project and select “Open Folder in File Explorer”.
In the explorer window, there will be a folder called “Service References”. Inside you’ll find a sub-folder that has the name of the namespace you gave your service reference. In my case “AX”. The folder contains XML schemas (xsd), datasource files, the C# files with the proxy code, etc. One particular file is of interest to us: Reference.svcmap. This file contains the URL for the service, the advanced settings for the proxy generation, etc (you can open with notepad, it’s an XML file). But the node called MetadataSources contains only one subnode, with the service URL. If we add a second node with a reference to our second URL, we can regenerate the proxies for both URLs within the same service reference, effectively forcing Visual Studio to reuse the proxies across the two URLs. So, let’s change the XML file as follows. Note that XML is case sensitive, and obviously the tags must match so make sure you have no typos. Also make sure to increment the SourceId attribute.
Original:

New:

Again, I can’t stress enough, don’t make typos, and make sure you use upper and lower case correctly as shown. Now, save the Reference.svcmap file and close it. Back in Visual Studio, right-click your original service reference, and click “Update Service Reference”.
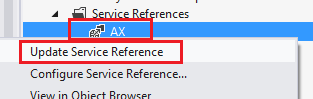
FYI, if you select “Configure Service Reference” you’ll notice that compared to when we opened this from the Advanced button upon adding the reference, there is now a new field at the top that says “Address: Multiple addresses (editable in .svcmap file)”).
If you made no typos, your proxies will be updated and you are now the proud owner of a service reference for metadata service and query service, sharing the same proxies (basically, one service reference with two URLs). First, let’s create a method to execute a query.
<pre>static System.Data.DataSet ExecuteQuery(AX.QueryMetadata query)
{
AX.QueryServiceClient queryClient = new AX.QueryServiceClient();
AX.Paging paging = new AX.PositionBasedPaging() { StartingPosition = 1, NumberOfRecordsToFetch = 5 };
return queryClient.ExecuteQuery(query, ref paging); }
</pre></code>
Note that I use PositionBasedPaging to only fetch the first 5 records. You can play around with the paging, there are different types of paging you can apply. So now for the point of this whole article. We will change our Main method to fetch the query from the AOT, then execute it. For good measure, we’ll check if there is already a range on the AccountNum field on CustTable, and if so set it. Here I’m doing a little Linq trickery: I select the first (or default, meaning it returns null if it can’t find it) range with name “AccountNum”. If a range is found, I set its value to “2014” (a customer ID in my demo data set). Finally I execute the query and output the returned dataset’s XML to the console.
<pre>static void Main(string[] args)
{
AX.QueryMetadata query = GetQuery("CustTransOpen");
if (query != null)
{
var range = (from r in query.DataSources[0].Ranges where r.Name == "AccountNum" select r).FirstOrDefault();
if (range != null)
{
range.Value = "2014";
}
System.Data.DataSet dataSet = ExecuteQuery(query);
Console.WriteLine(dataSet.GetXml());
}
Console.ReadLine(); }</pre></code> And there you have it. We retrieved a query from the AOT, modified the query by setting one of its range values, then executed that query. Anything goes here, the metadata you retrieve can be manipulated like you would a Query object in X++. You can add more datasources, remove datasources, etc. For example, before executing the query, we can remove all datasource except "CustTable". Also make sure to clear order by fields since they may be referencing the other datasources. Again using some Linq trickery to achieve that goal. <code><pre>// Delete child datasource of our first datasource (custtable) query.DataSources[0].DataSources.Clear(); // Remove all order by fields that are not for the CustTable datasource query.OrderByFields.RemoveAll(f => f.DataSource != "CustTable");
</pre></code>
Apr 25, 2013 - Dynamics AX 2012 Compile Times
Filed under: #daxmusings #bizappsAs I’m sure most of you are aware, compile times in Dynamics AX 2012 are a concern with more functionality being added. Especially on our build environments, which are (non-optimized) virtual machines, we are looking at around 3 hours for AX 2012 RTM/FPK and around 5 hours for R2. There have been discussions on the official Microsoft Dynamics AX Forums about this very topic, and there seem to be huge differences in experiences of compile times. After a lot of discussion with other people on the forums, and consequent chats with Microsoft people that are “in the know”, I think it’s pretty clear which areas one needs to focus on to optimize compile times.
1) The AX compiler was originally built when there was no talk about multi-core. So, as a result, you’ve probably noticed a compile only uses one thread. With today’s trend of more cores but at lower clock speeds, an “older” machine (CPU type) may possibly perform better than a new one, or a desktop machine may perform better than a high-end server. 2) The communication between AX and SQL is critical. The communication with the model store is critical (AOS gets the source code from the model store, compiles it, puts the binaries back in the model store). 3) The model store is in SQL so SQL has to perform optimally.
To this end, I set out to build one of our customer’s code bases (AX 2012 RTM CU3, no feature pack) on an “experimental” build machine. This code base has been taking an average compile time of 3 to 3.2 hours every time on our virtual AOS connected with physical SQL.
The new setup? A Dell Latitude E6520 laptop:
- Core i7-2760QM CPU @ 2.4GHz, 4 Cores, 8 Logical Processors
- 8 GB memory
- High performance SSD (Samsung 840 Pro), 256GB
- Windows Server 2012, SQL 2012, AX 2012 RTM CU4
Besides this hardware (2.4ghz clock speed - number of cores doesn’t matter, SSD to maximize SQL throughput), the key elements of our setup are putting the AOS and the SQL server both on this same machine, and disabling TCP/IP in the SQL server protocols so that it uses shared memory instead. This is the least overhead you can possibly get between the AOS and SQL.
The difference in compile time is staggering. I actually ran it multiple times because I thought I had done something wrong. However, since this is an automated build using TFS, I know the steps and code and everything else is EXACTLY the same by definition. So…. drumroll! (Note I didn’t list some extra steps being done in the automated build explicitly so that’s why it may not seem to add up…)
| Old Build Server | New Build Server | |
| Remove old models | 00:00:27 | 00:00:03 |
| Start AOS | 00:01:26 | 00:00:25 |
| Synchronize (remove old artifacts from DB) | 00:06:52 | 00:05:57 |
| Import XPOs from TFS | 00:13:17 | 00:03:55 |
| Import VS Projects | 00:00:29 | 00:00:11 |
| Import Labels | 00:00:22 | 00:00:08 |
| Synchronize (with new data model) | 00:05:42 | 00:01:55 |
| X++ Compile | 02:29:36 | 00:41:28 |
| CIL Generation | 00:13:41 | 00:05:29 |
| Stop AOS | 00:00:10 | 00:00:03 |
| Export Built Model | 00:00:42 | 00:00:12 |
| Total Build Time | 03:14:43 | 01:00:59 |
So yes, the compile time got down to 41 minutes! We’ve actually switched using this machine somewhat permanently for a few customers, we’ll be switching more. Now I need another machine for R2 compiles :-) I will post the compile times for R2 when I get to those.
Happy optimizing! :-)
Apr 16, 2013 - Exception Handling in Dynamics AX
Filed under: #daxmusings #bizappsException handling in Dynamics AX is a topic that is not discussed too often. I figured I would provide a quick musing about some of my favorite exception handling topics.
Database Transactions Exception handling while working with database transactions is different. Unfortunately, not a lot of people realize this. Most exceptions cannot be caught within a transaction scope. If you have a try-catch block within the ttsBegin/ttsCommit scope, your catch will not be used for most types of exceptions thrown. What does happen is that AX will automatically cause a ttsAbort() call and then look for a catch block outside of the transaction scope and execute that if there is one. There are however two exception types you CAN catch inside of a transaction scope, namely Update Conflict and Duplicate Key (so don’t believe what this MSDN article says). The reason is that it allows you to fix the data issue and retry the operation. You see this pattern in AX every now and then, you have a maximum retry number for these exceptions, after which you throw the “Not Recovered” version of the exception. The job below shows a generic X++ script that loops through each exception type (defined by the Exception enumeration), throws it, and tries to catch it inside a transaction scope. The output shows if the exception is caught inside or outside the transaction scope.
<pre>static void ExceptionTest(Args _args)
{
Exception exception;
DictEnum dictEnum;
int enumIndex;
dictEnum = new DictEnum(enumNum(Exception));
for (enumIndex=0; enumIndex < dictEnum.values(); enumIndex++)
{
exception = dictEnum.index2Value(enumIndex);
try
{
ttsBegin;
try
{
throw exception;
}
catch
{
info(strFmt("%1: Inside", exception));
}
ttsCommit;
}
catch
{
info(strFmt("%1: Outside", exception));
}
} }
</pre></code>
Fall Through
Sometimes you just want to catch the exception but not do anything. However, an empty catch block will result in a compiler warning (which of course we all strive to avoid!). No worries, you can put the following statement inside your catch block:
Global::exceptionTextFallThrough()
Of course, you’re assuming the exception that was thrown already provided an infolog message of some sort. Nothing worse than an error without an error message.
.NET Interop Exceptions
When a .NET exception is thrown, they are typically “raw” exceptions compared to our typical ‘throw error(“message here”)’ informative exceptions. I’ve seen quite a lot of interop code that does not even try to catch .NET call exceptions, let alone handle them. The following examples show different tactics to show the actual .NET exception message. Note that not catching the error (trying to parse “ABCD” into an integer number) does not result in ANY error, meaning a user wouldn’t even know any error happened at all.
Strategy 1: Get the inner-most exception and show its message:<pre>static void InteropException(Args _args)
{
System.Exception interopException;
try
{
System.Int16::Parse("abcd");
}
catch(Exception::CLRError)
{
interopException = CLRInterop::getLastException();
while (!CLRInterop::isNull(interopException.get_InnerException()))
{
interopException = interopException.get_InnerException();
}
error(CLRInterop::getAnyTypeForObject(interopException.get_Message()));
} }
</pre></code>
Strategy 2: Use ToString() on the exception which will show the full stack trace and inner exception messages:<pre>static void InteropException(Args _args)
{
System.Exception interopException;
try
{
System.Int16::Parse("abcd");
}
catch(Exception::CLRError)
{
interopException = CLRInterop::getLastException();
error(CLRInterop::getAnyTypeForObject(interopException.ToString()));
} }
</pre></code>
Strategy 3: Get all fancy and catch on the type of .NET exception (in this case I get the inner-most exception as we previously have done). Honestly I’ve never used this, but it could be useful I guess…<pre>static void InteropException(Args _args)
{
System.Exception interopException;
System.Type exceptionType;
try
{
System.Int16::Parse("abcd");
}
catch(Exception::CLRError)
{
interopException = CLRInterop::getLastException();
while (!CLRInterop::isNull(interopException.get_InnerException()))
{
interopException = interopException.get_InnerException();
}
exceptionType = interopException.GetType();
switch(CLRInterop::getAnyTypeForObject(exceptionType.get_FullName()))
{
case 'System.FormatException':
error("bad format");
break;
default:
error("some other error");
break;
}
} }
</pre></code>
throw Exception::Timeout;
Mar 27, 2013 - Performance Info from Convergence 2013
Filed under: #daxmusings #bizappsThis week at Convergence, I attended several sessions (and actually moderated an interactive discussion session) on performance in Dynamics AX. As expected, customers and partners showed up with specific questions on issues they are facing. Out of the three different sessions I was a part of, two major topics came up over and over again: how do we troubleshoot performance issues and how do we handle virtualization?
Microsoft has done benchmarking on virtualization using Hyper-V, by starting at an all-physical setup and iteratively benchmarking and virtualizing pieces of the Dynamics AX setup. The big picture reveals (not surprisingly) that the further a virtual component is from SQL, the less impact it has. I’ve been asked to wait to blog about this further as new benchmarks are being made on hyper-v 2012 which has an enormous amount of performance improvements. But, for more information and the currently available benchmark you can download the virtualization benchmark whitepaper (requires customer or partner source access).
The next obvious question around performance was how to troubleshoot it. Naturally there are multiple reasons one could have performance issues. It could be SQL setup, AOS setup, client setup, poorly designed customizations, etc. Each area has its tools to troubleshoot, so a gradual approach may be in order. First, the Lifecycle Services Microsoft will release in the second half of 2013 will have a system diagnostics tool available. This is what Microsoft calls “the low hanging fruit”, things that could be obvious setup or configuration issues that can be easily fixed and may make a significant difference in performance; things like buffer sizes, SQL tempdb location, debugging enabled on a production environment, etc. This tool will currently only support AX 2012 and up, I have not heard any plans to support earlier versions of AX. As mentioned earlier, the tool is scheduled to be released the second half of 2013. Pricing for the service which includes a whole range of tools (more on this in another post) is currently not released, but in general lines it will be tied to the level of support plan a customer has with Microsoft.
Next up is the Trace Parser. The trace parser will allow you to trace a particular scenario and give feedback on the code being called, calls between client and server, time spent on every call, etc. This will give you a good idea on what is going on behind the covers of a specific process. Besides its use in troubleshooting performance issues, this is a really good tool during development to do code tracing in the standard application or augmenting other debugging efforts. You can download the trace parser (for free) here (requires customer or partner source access)
Finally there is the dynamics perf tool. This will do a deep dive on your SQL server, give you things like top 10 queries, index usage (or lack thereof) etc. This is knee-deep SQL troubleshooting and will give you a broad range of statistics and suggestions to optimize your SQL setup and can identify issues with missing indexes or poor performing queries in your application code (note this is strictly a SQL tool so you won’t see any tracing back to the source code). You can find the dynamics perf tool (for free) here.
Somewhat surprisingly, a show of hands in my session revealed most customers were unaware of the availability of these tools and what they could do, so spread the word!
And last but not least there were some announcements on a load testing / benchmarking tool that we should see released in the next month or so. It will allow you to setup scenarios such as entering sales orders, creating journals etc, and then allow for mass-replay of these scenarios in AX to test performance. The tools are based on the Visual Studio load testing tool and basically provide an integration with AX. I will make sure to keep you updated on more details and release dates when that information becomes available.
All in all a lot of learning went on at Convergence on the performance topic. Also visit the blog of the Microsoft Dynamics AX Performance Team to stay current on any other tools or whitepapers they are releasing.
Mar 14, 2013 - Convergence 2013
Filed under: #daxmusings #bizappsFor those of you waiting on the continuation of the TFS series - please be patient. Next week is Convergence and a lot of time and energy is being put into preparing both our Sikich company booth (#2437) and material, as well as the Interactive Discussion session I will be leading there. Topic at hand in my session is optimizing performance in code and sql. Session IDAX07 in the session catalog, held Thursday from 11am - 12pm. This is an interactive discussion so the idea is that I talk as little as possible, and have you, the audience, ask questions and answer questions and share experience with your peers. I will have some Microsoft performance experts (Christian Wolf and Gana Sadasivam) there as well for those ultra-tough questions that your peers or myself don’t know how to answer :-)
If you are unable to attend, I do recommend following the virtual conference and attend any keynotes/sessions you deem relevant. It’s always great to find out about features you didn’t know of, or get a feel for where your favorite Dynamics product is headed. As far as social media you can also follow the “Convergence Wall”. I will be tweeting and blogging about Convergence next week. You can follow me on Twitter @JorisdG.
If you are attending Convergence 2013, come see me at my session on Thursday, or visit me at the Sikich booth Monday afternoon or early Tuesday afternoon. Otherwise, look for me walking around. Like last year, I will be sporting my fedora (see below).
Mar 1, 2013 - How We Manage Development - Organizing TFS
Filed under: #daxmusings #bizappsIn the first post, I presented an overview of how we have architected our development infrastructure to support multiple clients. In this article, we will look at how we organize TFS to support our projects.
Team Foundation Server contains a lot of features to support project management. We have chosen to keep Team Foundation Server a developer-only environment, and manage the customer-facing project management somewhere else using SharePoint. In fact, even our business consultants and project managers do not have access or rarely see this magical piece of software we call TFS. (I bet you some are reading these articles to find out!) There are several reasons for this, and these are choices we have made that I’m sure not everyone agrees with.
- Developers don’t like to do bookkeeping. We want to make sure the system is efficient and only contains information that is relevant to be read or updated by developers.
- We need a filter between the development queue and the user/consultant audience. Issues can be logged elsewhere and investigated. AX is very data and parameter driven so a big portion of perceived “bugs” end up to be data or setup related issues. If anyone can log issues or bugs in TFS and assign them to a developer, the developers will quickly start ignoring the lists and email alerts because there are too many of them. TFS is actual development work only, any support issues or investigative tasks for developers/technical consultants are outside of our TFS scope.
- Another reason to filter is project scope and budget. Being agile is hot these days, but there is a timeline and budget so someone needs to manage what is approved for the developers to work on. Only what is approved gets entered in TFS, so that TFS is the actual development queue. That works well, whether you go waterfall or agile.
- Finally, access to TFS means access to a lot of data. There are security features in TFS, of course, but they are nothing like XDS for example. This means check-in comments, bug descriptions, everything would be visible. There are probably ways to get this setup correctly, but for now it’s an added bonus of not having to deal with that setup.
Each functional design gets its own requirement work item in TFS. Underneath, as child workitems, we add the development “tasks”. Initially, we just add one “initial development” task. We don’t actually split out pieces of the FDD, although we easily could i guess. When we get changes, bugs, basically any change after the initial development, we add another sub-task we can track. So, for example, the tasks could look like this in TFS:

This allows us to track any changes after the initial development/release of the code for the FDD. We can use this as a metric for how good we are doing as a development group (number of bugs), how many change requests we get (perhaps a good measure of the quality of the FDD writing), etc. It also allows us to make sure we don’t lose track of loose ends in any development we do. When a change is agreed upon, the PM can track our TFS number for that change. If the PM doesn’t have a tracking number, it means we never got the bug report. It is typically the job of the project’s development lead to enter and maintain these tasks, based on emails, status calls with PMs, etc. I will explain more about this in the next article.
On to the touchy topic of branching. There are numerous ways to do this, all have benefits and drawbacks. If you want to know all about branching and the different strategies, you can check out the branching guide written by the Microsoft Visual Studio ALM Rangers. It is very comprehensive but an interesting read. There is no one way of doing this, and what we chose to adopt is loosely based on what the rangers call the “code promotion” plan.
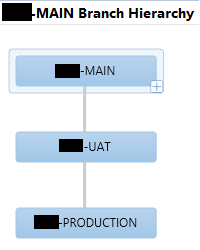
Depending on the client we may throw a TEST branch in between MAIN and UAT. We have played with this a lot and tried different strategies on new projects. Overall this one seems to work best, assuming you can simplify it this way. Having another TEST in between may be necessary depending on the complexity of the implementation (factors such as client developers doing work on their systems as well - needing a merge and integrated test environment, or a client that actually understands and likes the idea of a pure UAT - those are rare). One could argue that UAT should always be moved as a whole into your production environment. And yes, that is how it SHOULD be, but few clients and consultant understand and want that. But, for that very reason, and due to the diversity of our clients’ wants and needs, we decided on newer projects to make our branches a bit more generic, like this:
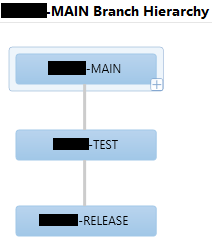
This allows us to be more consistent in TFS across projects, while allowing a client to apply these layers/models as they see fit. It also allows us to change strategies as far as different environment copies at a client, and which code to apply where. All without being stuck with defining names such as “UAT” or “PROD” in our branch names.
So, the only branch that is actually linked to Dynamics AX is the MAIN branch. Our shared AOS works against that branch, and that is it. Anything beyond that is ALL done in Visual Studio Explorer. We move code between branches using Visual Studio. We do NOT make direct changes in any other branch but MAIN. Moving code through branch merging has a lot of benefits.
1) We can merge individual changes forward, such as FDD03, but leave FDD04 in MAIN so it is not moved. This requires developers to ALWAYS do check-ins per FDD, never check-in code for multiple FDDs at the same time. That is critical, but makes sense - you’re working on a given task. When you go work on something else (done or not), you check in the code you’re putting aside, and check out your next task. 2) By moving individual changes, TFS will automatically know any conflicts that arise. For example, FDD02 may add a field to a table, and the next FDD03 may also add a field to that same table. But both fields are in the same XPO in TFS - the table’s XPO. Now, TFS knows which change you made when… so whether we want to only move FDD02, or only FDD03, TFS will know what code changes belongs to which. (more on this in the next article) This removes the messy, manual step of merging XPOs on import. 3) The code move in itself becomes a change as well. For clients requiring strict documentation for code moves (SOx for example), the TFS tracking can show that in the code move, no code was changed (ie proving that UAT and PROD are the same code). We also get time stamps of the code move, user IDs, etc. Perfect tracking, for free. 4) With the code move itself being a change set, we can also easily REVERT that change if needed. 5) It now becomes easy to see which pieces of code have NOT been moved yet. Just look for pending merges between branches.
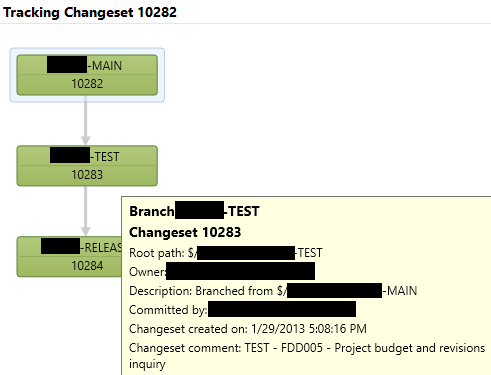
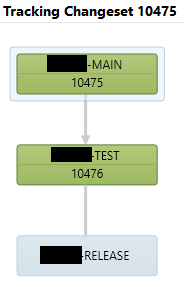
So, I can look at my history of changes in MAIN, and inquire into the status of an individual change. In the first screenshot, you see a changeset that was merged all the way into RELEASE. My mouse is hovered over the second branch (test) and you can see details. The second screenshot shows a change that has not been moved into RELEASE yet.
Obviously you can also get lists of all pending changes etc. We actually have some custom reports in that area, but you can get that information out of the box as well.
So, for any of you that have played with this and branching, the question looming is: how can you merge all changes for one particular FDD when there are multiple people working on multiple FDDs. TFS does not have a feature to “branch by work item” (if you check in code associating it to a work item, one could in theory decide to move all changes associated with that work item, right?). Well, the easiest way we found is to make sure the check-in comment is ALWAYS preceded with the FDD number. So, when I need to merge something from MAIN to TEST, I just pick all the changesets with that FDD in the title:
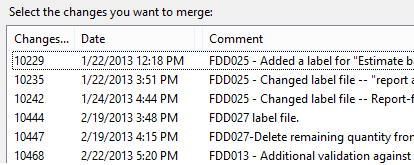
Yes, you may need several merges if there are a lot of developers doing a lot of changes for a lot of FDDs. However, it forces you to stay with it, and it actually gets better: if you merge 5 changesets for the same FDD at the same time, the next merge further down to the next branch will only be for the 1 merge-changeset (which contains all 5). Also consider the alternative of you moving the XPOs manually and having to strip out all the unrelated code during the import. After more than 2 years of using TFS heavily, I know what I prefer :-) (TFS, FYI).
Once code is merged, all that needs to happen is a right-click by the lead developer to start a new build - no further action required. This will spin up TFS build using our workflow steps, which imports all the code, compiles, and produces the layer (ax 2009) or model (ax 2012). More details on this in the next article.
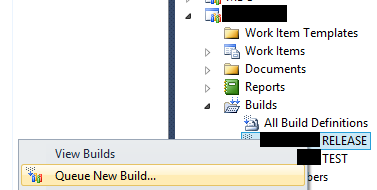
Once the build is completed (successfully or not), we get an alert via email. If the build was successful, the model or layer will be on a shared folder - ready to be shipped to the client for installation, with certainty that it compiles. We actually have a custom build report we can then run which, depending on the client’s needs, will show which FDDs and which tasks/bugs were fixed in this release, potentially a list of the changed objects in the build, etc. Without the custom report, here’s what standard TFS will give you:
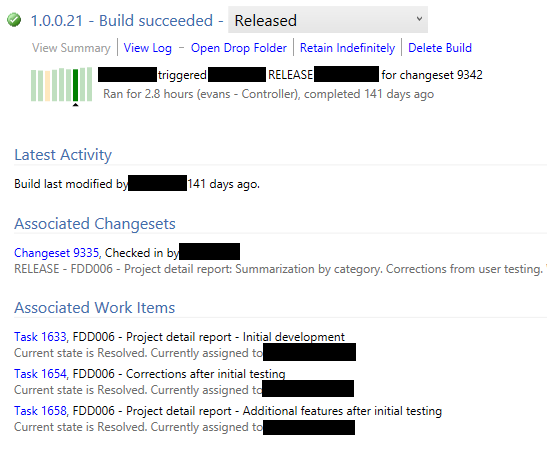
As you can tell by the run time (almost 3 hours), this is AX 2012 :-)
This has become a lengthy post, but hopefully interesting. Next article, I will show you some specific examples (including some conflicts in merging etc) - call it a “day in the life of a Sikich AX developer”…
Feb 28, 2013 - How We Manage Development - Architecture
Filed under: #daxmusings #bizappsWith all the posts about TFS and details on builds etc, I thought it was time to take a step back and explain how we manage development in general. What infrastructure do we have, how does this whole TFS business work in reality?! Let me take you through it.
First, let’s talk about our architecture. We currently have two Hyper-V servers. These host a development server per client. These development servers contain almost everything on them except AX database, we use a physical SQL server for that. So the development servers contain AOS, SSRS/SSAS, SharePoint/EP, Help Server and IIS/AIF (where needed). Each development server is tied to a specific project in TFS for that client. In addition to the main AOS that is used to develop in (yes we still do the “multiple developers - one AOS” scenario), there is a secondary AOS on each machine that is exclusively used for the builds. Typically developers do not have access to this AOS or at least never go in (in fact the AOS is usually shut off when it’s not building, to save resources on the virtual machine).
There are several advantages to having a virtual development server per client:
- Each server can have whichever version of AX kernel we need (potentially different versions of SQL etc)
- If clients wish to perform upgrades we can do that without potentially interfering with any other environments
- Any necessary third-party software can be installed without potentially interfering with any other environments
- The virtual servers can be shut down or archived when no development is being done
I’m sure there is more, but those are the obvious ones.
Traditionally, VARs perform the customer development on a development server at the customer site. We used to do this as well (back in the good ol’ days). There are several drawbacks to that:
- Obviously it requires an extra environment that, if the client is not doing their own development, may solely be for the consultant-developers. With AX 2012 resource requirements per AOS server have skyrocketed and some clients may not have the resources or budget to support another environment.
- We need source control. This is the 21st century, developing a business-critical application like AX without some form of source control is irresponsible. MorphX source control can be easily used (although it has limited capabilities), but any other source control software (that integrates with AX) requires another license of sorts, in case of TFS you also need a SQL database, etc. Especially for clients not engaging in development efforts, this is a cost solely to support the consultant-developers.
- Segregation of code and responsibilities between VAR and clients that do their own development. Developing in multiple layers is the way to do that. But working with multiple developers in multiple layers (or multiple models) with version control enabled is a nightmare.
- No easy adding of more resources (=developers) for development at critical times, since remote developers need remote access, user accounts, VPNs, etc. Definitely doable, but not practical.
As with most things development in the Dynamics AX world, any new customer has no issue with this and finds it logical and accepts the workflow of remote development, deploying through builds, etc. It is always customers that have implemented AX the traditional way (customers upgrading, etc) that have a hard time changing. It is interesting how this conflicts with a lot of VARs switching to off-shore development, essentially the ultimate remote development scenario. At our AX practice within Sikich we only use internal developers that work out of our Denver office. (Want to join us in Denver?)
We don’t have all of our clients up on this model, but all new clients are definitely setup this way. As of this writing, we have 11 AX2009 client environments and 9 AX2012 client environments running on our Hyper-Vs and tied into and managed by TFS.
With that out of the way, we’ll look at our TFS setup in the next post.
Feb 7, 2013 - AX 2012's Hidden Compile Errors
Filed under: #daxmusings #bizappsThis post title caught your attention huh? Well, it should. For about half a year or longer now, we’ve been struggling with a strange issue with AX 2012 compiles. We finally found more or less what the issue was, but were unable to reliably replicate the issue. Finally in October, one of our developers here at Sikich took the time to replicate an existing issue in a vanilla AX environment and was able to reliably replicate the issue for Microsoft to investigate. And I’m glad to say that we now officially received a kernel hotfix.
For future reference, this issue pertains to all current versions of AX 2012 as of this date (February 6th, 2013). This means:
AX 2012 RTM AX 2012 CU1 AX 2012 CU2 AX 2012 CU3 AX 2012 CU4 AX 2012 FPK AX 2012 FPK CU3 AX 2012 FPK CU4 AX 2012 R2
Obviously if you received kernel hotfixes for any of these versions, you may have received this kernel hotfix as well. I don’t have build numbers for all of these yet.
Ok, so on to the issue. As you are probably aware as a reader of this blog, we heavily rely on automated builds using TFS. We started noticing builds completing successfully without error, but once installed at a client they resulted in compile errors. Depending on the type of error this may or may NOT result in a CIL generation error as well. We found out that indeed there were compile errors, but they were never captured in our automated build. Turns out that it is not our build process, but AX that is not reporting the compile errors.
Let me provide you with the example we gave Microsoft. Note this is not a direct CODE example per se, but a compile error nonetheless. There are plenty of other opportunities for compile errors not being thrown, this is just one easy and quick example. Things we saw were missing methods, missing variable declarations, all sorts of things that SHOULD result in a compile error but weren’t. Note that an individual compile on only 1 object always results in an error correctly, this issue applies to full compiles or multiple-object compiles (full AOT compile, compiling an AOT project, etc).
Let’s start by creating a new project for a service we’ll be creating. I called mine “DMTestService”. Next, we’ll create a service. We create a new class called “TestServiceClass”, and add a method “MyOperation”. I’m not going to put any code in it since we’re just interested in the compile error and not in it actually doing anything.

<pre>[SysEntryPointAttribute]
public void MyOperation()
{
}</pre>
Next, we create a new service (right-click the project and select New > Service or go to the Services node in the AOT, right-click it and select “New Service”). We will call this service “TestService”. Right-click the new TestService and select “Properties”. In the properties find the “Class” property, and enter the name of the class we created previously (in my case “TestServiceClass”).
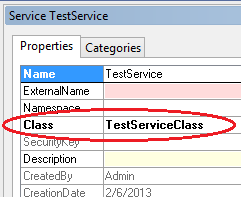
Next, right-click on the “Operations” node under your service, and select “Add Operation”.
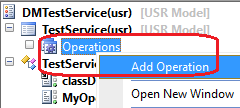
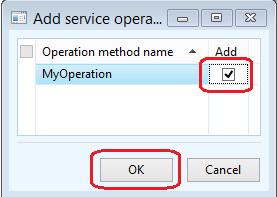
On the Add Service Operation dialog, click the Add checkbox for the MyOperation method, and click OK. This will add the operation to the service.
Alright, good enough. So now if you right-click compile the service, no errors. Now let’s break this! Open the MyOperation method on the TestServiceClass and make the method static.
<pre>[SysEntryPointAttribute]
public static void MyOperation()
{
}</pre>
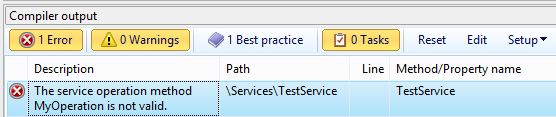
This will make the operation on your service invalid, as there is no longer an instance method called “MyOperation”. And indeed, if you right-click on the TestService and select “Compile”, you get this compile error:
And now what we’ve all been (not so much) waiting for… Right-click your PROJECT and select compile… The error goes away… no errors in the project!! If you take an XPO of this and import somewhere else, you’ll also notice the XPO import does not throw a compile error. If you do a full AOT compile, no error is thrown.
For those of you questioning if this really is a compile error, it’s not about the TYPE of compile error necessarily, the problem is errors are reported in the compiler output but cleared out later. The issue has to do with the number of compile passes AX does.
Thanks to the members of my development team to figure out an easy way to reproduce the issue so we could report to Microsoft!
If you wish to get the hotfix from Microsoft support, the KB number is 2797772. It is listed on the “hotfixes” page on PartnerSource, if you have access to that (no download link, you’ll have to request it from Microsoft).
Jan 9, 2013 - Fixing code caching on AX environment copies
Filed under: #daxmusings #bizappsCopying AX environments and their databases is a fact of life. You need data refreshed, you want an exact replica to troubleshoot something, or you just need a good copy to do training or testing on. Cloning environments and database is fairly easy and a fairly quick thing to do. The major work is typically done after the copy… fixing links to attachment folders, help server, report server, AIF, etc. However, there is one tiny issue that can crop up, and honestly in my decade of AX I’ve only actually seen this present itself very clearly only ONCE (this was in AX 2009). And it has to do with caching of code.
AX caches code for a client by means of an AUC file (axapta user cache). This file located in %userprofile%\AppData\Local (which translates to something like c:\users\YOURUSER\AppData\Local). The file takes a name of AX_{GUID}.auc, where the guid represents the instance of AX that the cache file is for. For example, if this user has access to a test and a production environment, the cache is kept separate, as the code is not necessarily the same. But as you could have guessed from the title and this introduction, when you copy environments this GUID can be copied as well, resulting in the same cache file being used for different environments (uh-oh).
I will show you a “cool” example of what can happen. For this example with AX 2012, I have a blank environment (ie a blank initialized database with only standard code). This will reduce the amount of time for me to backup/restore. Obviously, this will work with any database with any data and code. Let’s create a new class (I’ll be creative and keep the default name “Class1”). We create a main method, but we’re explicitly telling it to run on client (since we need to make sure we hit that cache), and the only statement we’ll put in is an infolog:
<pre>public client static void Main(Args _args)
{
info("Message from Class");
}</pre>
If we run the class (right-click the class, click “Open”; or just from the code editor window press F5), we’ll see the expected infolog. Close your AX client and let’s clone this environment.
The quick way to clone the database is to open the SQL Server Management Studio, locate the existing database, right-click the database and select “Tasks > Back Up…”. If you are dealing with a database that is regularly backed up with third party software or using the built-in maintenance plans, make sure to check the “Copy-only Backup” checkbox to avoid messing with the transaction log. In the destination section, save the BAK file somewhere you can remember. Click OK to take the backup. When done, right-click the “Databases” node in the object explorer pane and select “Restore Files and Filegroups…”. Enter a new (non-existing) database name in the “To database” field. Select the “From device” radio button and use the lookup there to locate your freshly taken backup. Click ok to restore. Now all you need to do is to point your second AOS to this new, copied database.
Alright, on to the fun part. Before starting any clients, it’s interesting to delete all the *.AUC files you may have in your %userprofile%\AppData\Local folder. First, let’s open the client into the original environment. In the AOT, find the Class1 class and right-click, select Open. Not surprisingly, nothing changed and this wonderful greeting comes your way.
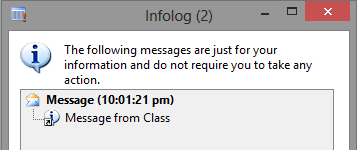
CLOSE THE CLIENT. Note that after closing, your %userprofile%\AppData\Local folder will have a AUC file again. Next, we open the client into the COPY environment. Locate Class1 in the AOT and again right-click/Open. Obviously, same message appears. Now, here’s where it gets interesting. Open the main method on Class1, and change the text.
<pre>public client static void Main(Args _args)
{
info("Different Message from Class");
}</pre>
Now run the class. Again, quite expectedly, the infolog shows our new message. Let’s now close this client, and give it the opportunity to update the cache file.
For the grand finale, let’s open up our ORIGINAL environment again. Go in the AOT and run Class1. What does the infolog say?
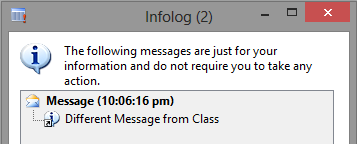
Now open that class in the AOT… what does the code say?
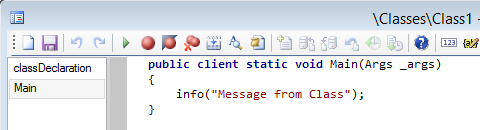
Yes indeed. Although the code still has our original message (as it should, that’s what’s in the AOT), the client used the cached version of the class at run time, and the last update to the cache file was our change in the COPY environment. So what if we change this message here again? Well, in my testing at that point both environments correctly showed their messages. I can only guess this is due to the actual mechanism the client uses to decide to refresh its cache (save count? timestamp?). If anyone tests this further or actually knows, feel free to comment below. I have seen this once at a client environment (on AX 2009) that I could keep this cache thing going… update one environment, and the other one uses that cache. Back and forth.
Alright, so enough fun. How do we resolve this?? Well, after taking the database copy, you need a minor tweak in a system table in SQL. For your copied database, locate the SYSSQMSETTINGS table in SQL (open the SQL Server Management Studio, in the object explorer expand your database, expand tables, and find the SYSSQMSETTINGS table). Note this table is not accessible in AX, only in SQL. Right-click on the table and select “Edit Top 200 Rows”. In the row view, you’ll find one record only, and a column named “GLOBALGUID”. Not surprisingly, that guid is the guid you’ll find in the name of your cache file. Just set the guid to all zeros, and restart the AOS (the AOS will regenerate a new guid at startup if it’s blank). Quickest way is to run an update script:
update SYSSQMSETTINGS SET GLOBALGUID = ‘{00000000-0000-0000-0000-000000000000}’
Now your databases have different GUIDs, and consequently different client cache files!! Infolog messages are fun, but who knows what your code is doing with the wrong cache?!
Jan 7, 2013 - Multi-select on form datasource grid : MultiSelectionHelper
Filed under: #daxmusings #bizappsIn Dynamics AX it has traditionally been somewhat cumbersome to iterate the selected records on a form datasource. The main issue is that there is a difference in iterating depending on how and what the user has selected!
For example, I have a simple form with a grid. The form has three buttons with their clicked method overwritten.
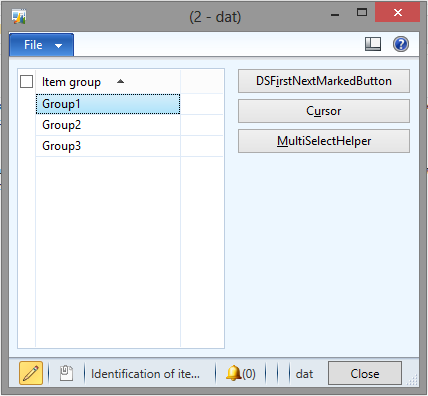
Dynamics AX allows you to iterate marked records on the grid. Assume our datasource is called “InventItemGroup”, which means we can access the object using “InventItemGroup_DS”. To iterate the marked records, you can call getFirst, and inside a loop call .getNext() until no more record is returned. The below code is the code behind door, erh, button number 1.
<pre>void clicked()
{
InventItemGroup itemGroup;
itemGroup = InventItemGroup_DS.getFirst(1);
while (itemGroup.RecId != 0)
{
info(itemGroup.ItemGroupId);
itemGroup = InventItemGroup_DS.getNext();
} }</pre></code>
Looks good. Unfortunately, this works ONLY when you actually MARK a record (in versions prior to AX 2012, when you click the little button in front of a row, in AX2012 when you click the checkbox). If you just select a line by clicking in one of the columns, the one record will not be picked up.
For example, this scenario results in, well, nothing.
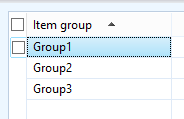
These two examples below will result in the expected behavior (getting the item group in the infolog, that is).
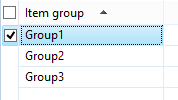
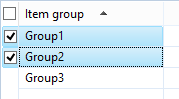
As I’m sure you aware, you can also get the current record by just accessing the datasource directly. In the case of our example, InventItemGroup.
<pre>void clicked()
{
info(InventItemGroup.ItemGroupId);
}</pre>
With one record selected, this obviously will work. So what happens with multiple records select? It will give you back the LAST record you clicked on. As an example, click one record, then hold the CTRL button on your keyboard pressed and select the next record. The code above will return the ItemGroupId of the last record you clicked on. If you reverse the order in which you clicked the records, you will see that.
So now, the easy way to fix this, is to combine both methods. This is “traditional” code as seen in all versions of Dynamics AX. If the getFirst() method does not return anything, take the datasource cursor instead.
But of course, there’s a better way in Dynamics AX 2012. A class called “MultiSelectionHelper” will do the heavy lifting for you. It does in fact do some extra checking as well, feel free to read the code behind it.
<pre>void clicked()
{
InventItemGroup itemGroup;
MultiSelectionHelper helper = MultiSelectionHelper::construct();
helper.parmDatasource(InventItemGroup_DS);
itemGroup = helper.getFirst();
while (itemGroup.RecId != 0)
{
info(itemGroup.ItemGroupId);
itemGroup = helper.getNext();
} }</pre></code>
Happy coding. :-)
Blog Links

Blog Post Collections
- The LLM Blogs
- Dynamics 365 (AX7) Dev Resources
- Dynamics AX 2012 Dev Resources
- Dynamics AX 2012 ALM/TFS
Recent Posts
-
GPT4-o1 Test Results
Read more... -
Small Language Models
Read more... -
Orchestration and Function Calling
Read more... -
From Text Prediction to Action
Read more... -
The Killer App
Read more...