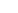 Menu
Menu
How We Manage Development - Organizing TFS
Filed under: #daxmusings #bizapps
In the first post, I presented an overview of how we have architected our development infrastructure to support multiple clients. In this article, we will look at how we organize TFS to support our projects.
Team Foundation Server contains a lot of features to support project management. We have chosen to keep Team Foundation Server a developer-only environment, and manage the customer-facing project management somewhere else using SharePoint. In fact, even our business consultants and project managers do not have access or rarely see this magical piece of software we call TFS. (I bet you some are reading these articles to find out!) There are several reasons for this, and these are choices we have made that I’m sure not everyone agrees with.
- Developers don’t like to do bookkeeping. We want to make sure the system is efficient and only contains information that is relevant to be read or updated by developers.
- We need a filter between the development queue and the user/consultant audience. Issues can be logged elsewhere and investigated. AX is very data and parameter driven so a big portion of perceived “bugs” end up to be data or setup related issues. If anyone can log issues or bugs in TFS and assign them to a developer, the developers will quickly start ignoring the lists and email alerts because there are too many of them. TFS is actual development work only, any support issues or investigative tasks for developers/technical consultants are outside of our TFS scope.
- Another reason to filter is project scope and budget. Being agile is hot these days, but there is a timeline and budget so someone needs to manage what is approved for the developers to work on. Only what is approved gets entered in TFS, so that TFS is the actual development queue. That works well, whether you go waterfall or agile.
- Finally, access to TFS means access to a lot of data. There are security features in TFS, of course, but they are nothing like XDS for example. This means check-in comments, bug descriptions, everything would be visible. There are probably ways to get this setup correctly, but for now it’s an added bonus of not having to deal with that setup.
Each functional design gets its own requirement work item in TFS. Underneath, as child workitems, we add the development “tasks”. Initially, we just add one “initial development” task. We don’t actually split out pieces of the FDD, although we easily could i guess. When we get changes, bugs, basically any change after the initial development, we add another sub-task we can track. So, for example, the tasks could look like this in TFS:

This allows us to track any changes after the initial development/release of the code for the FDD. We can use this as a metric for how good we are doing as a development group (number of bugs), how many change requests we get (perhaps a good measure of the quality of the FDD writing), etc. It also allows us to make sure we don’t lose track of loose ends in any development we do. When a change is agreed upon, the PM can track our TFS number for that change. If the PM doesn’t have a tracking number, it means we never got the bug report. It is typically the job of the project’s development lead to enter and maintain these tasks, based on emails, status calls with PMs, etc. I will explain more about this in the next article.
On to the touchy topic of branching. There are numerous ways to do this, all have benefits and drawbacks. If you want to know all about branching and the different strategies, you can check out the branching guide written by the Microsoft Visual Studio ALM Rangers. It is very comprehensive but an interesting read. There is no one way of doing this, and what we chose to adopt is loosely based on what the rangers call the “code promotion” plan.
Depending on the client we may throw a TEST branch in between MAIN and UAT. We have played with this a lot and tried different strategies on new projects. Overall this one seems to work best, assuming you can simplify it this way. Having another TEST in between may be necessary depending on the complexity of the implementation (factors such as client developers doing work on their systems as well - needing a merge and integrated test environment, or a client that actually understands and likes the idea of a pure UAT - those are rare). One could argue that UAT should always be moved as a whole into your production environment. And yes, that is how it SHOULD be, but few clients and consultant understand and want that. But, for that very reason, and due to the diversity of our clients’ wants and needs, we decided on newer projects to make our branches a bit more generic, like this:
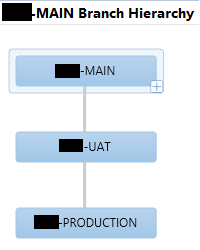
This allows us to be more consistent in TFS across projects, while allowing a client to apply these layers/models as they see fit. It also allows us to change strategies as far as different environment copies at a client, and which code to apply where. All without being stuck with defining names such as “UAT” or “PROD” in our branch names.
So, the only branch that is actually linked to Dynamics AX is the MAIN branch. Our shared AOS works against that branch, and that is it. Anything beyond that is ALL done in Visual Studio Explorer. We move code between branches using Visual Studio. We do NOT make direct changes in any other branch but MAIN. Moving code through branch merging has a lot of benefits.
1) We can merge individual changes forward, such as FDD03, but leave FDD04 in MAIN so it is not moved. This requires developers to ALWAYS do check-ins per FDD, never check-in code for multiple FDDs at the same time. That is critical, but makes sense - you’re working on a given task. When you go work on something else (done or not), you check in the code you’re putting aside, and check out your next task. 2) By moving individual changes, TFS will automatically know any conflicts that arise. For example, FDD02 may add a field to a table, and the next FDD03 may also add a field to that same table. But both fields are in the same XPO in TFS - the table’s XPO. Now, TFS knows which change you made when… so whether we want to only move FDD02, or only FDD03, TFS will know what code changes belongs to which. (more on this in the next article) This removes the messy, manual step of merging XPOs on import. 3) The code move in itself becomes a change as well. For clients requiring strict documentation for code moves (SOx for example), the TFS tracking can show that in the code move, no code was changed (ie proving that UAT and PROD are the same code). We also get time stamps of the code move, user IDs, etc. Perfect tracking, for free. 4) With the code move itself being a change set, we can also easily REVERT that change if needed. 5) It now becomes easy to see which pieces of code have NOT been moved yet. Just look for pending merges between branches.
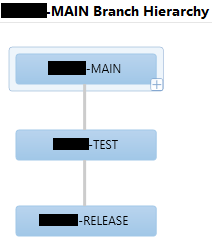
So, I can look at my history of changes in MAIN, and inquire into the status of an individual change. In the first screenshot, you see a changeset that was merged all the way into RELEASE. My mouse is hovered over the second branch (test) and you can see details. The second screenshot shows a change that has not been moved into RELEASE yet.
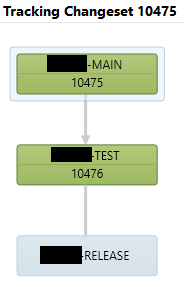
Obviously you can also get lists of all pending changes etc. We actually have some custom reports in that area, but you can get that information out of the box as well.
So, for any of you that have played with this and branching, the question looming is: how can you merge all changes for one particular FDD when there are multiple people working on multiple FDDs. TFS does not have a feature to “branch by work item” (if you check in code associating it to a work item, one could in theory decide to move all changes associated with that work item, right?). Well, the easiest way we found is to make sure the check-in comment is ALWAYS preceded with the FDD number. So, when I need to merge something from MAIN to TEST, I just pick all the changesets with that FDD in the title:
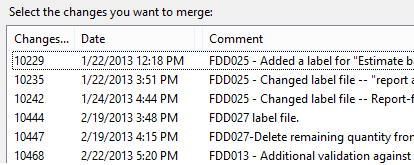
Yes, you may need several merges if there are a lot of developers doing a lot of changes for a lot of FDDs. However, it forces you to stay with it, and it actually gets better: if you merge 5 changesets for the same FDD at the same time, the next merge further down to the next branch will only be for the 1 merge-changeset (which contains all 5). Also consider the alternative of you moving the XPOs manually and having to strip out all the unrelated code during the import. After more than 2 years of using TFS heavily, I know what I prefer :-) (TFS, FYI).
Once code is merged, all that needs to happen is a right-click by the lead developer to start a new build - no further action required. This will spin up TFS build using our workflow steps, which imports all the code, compiles, and produces the layer (ax 2009) or model (ax 2012). More details on this in the next article.
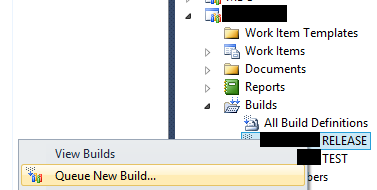
Once the build is completed (successfully or not), we get an alert via email. If the build was successful, the model or layer will be on a shared folder - ready to be shipped to the client for installation, with certainty that it compiles. We actually have a custom build report we can then run which, depending on the client’s needs, will show which FDDs and which tasks/bugs were fixed in this release, potentially a list of the changed objects in the build, etc. Without the custom report, here’s what standard TFS will give you:
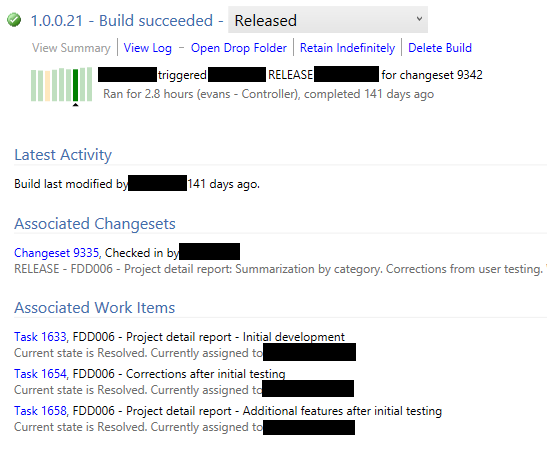
As you can tell by the run time (almost 3 hours), this is AX 2012 :-)
This has become a lengthy post, but hopefully interesting. Next article, I will show you some specific examples (including some conflicts in merging etc) - call it a “day in the life of a Sikich AX developer”…
There is no comment section here, but I would love to hear your thoughts! Get in touch!
Blog Links

Blog Post Collections
- The LLM Blogs
- Dynamics 365 (AX7) Dev Resources
- Dynamics AX 2012 Dev Resources
- Dynamics AX 2012 ALM/TFS
Recent Posts
-
GPT4-o1 Test Results
Read more... -
Small Language Models
Read more... -
Orchestration and Function Calling
Read more... -
From Text Prediction to Action
Read more... -
The Killer App
Read more...