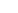 Menu
Menu
Microsoft Dynamics 365 / Power Platform - page 10
Oct 14, 2011 - Query Object Datasource Linking
Filed under: #daxmusings #bizappsThis is based on a question asked on the Microsoft Dynamics AX Community forums, you can find the original post here. I’ve been asked the question of adding datasources to a query object and linking them together a lot. The main issue exists around trying to use the .addLink() method on the datasource and how to avoid AX doing automatic linking.
First off, when I say automatic linking, this is not to be confused with DynaLink, which is what forms use to stay connected (when you select a new record in one form, the other form updates its query in relation to the form you selected in). What we’re talking about here is explicitly giving the relationship between two tables, using Query objects.
One thing to remember is that the query object and related objects represent a data structure which is the runtime variant of the modeled queries in the AOT. That also means, rather than creating the query in code completely, you can instantiate the query object based on the modeled query in the AOT by passing it the name of a query in the AOT, like so:
Query query = new Query(queryStr(Cust));
</code>where “Cust” is the name of a query in the AOT. That also means sorting, ranges, etc behave the same on the query object as they do on the modeled query in the AOT. That also means you can use the Query node in the AOT as your guideline.
Now, when linking two datasources, you have the option of either using whatever default relationship AX comes up with (based on the modeled relations on the tables), or you can specify your own relation between the tables. To do this successfully, there is a flag “Relations” on the datasource (both in AOT and the object). Unfortunately, in AX 2009, the AOT property “Relations” has a helptext that reads: “Specify whether database relations used for data source linking are explicitly giving”. This seems to imply setting the property to “yes” means you will be explicitly giving the relation. Unfortunately, it’s the other way around. This label was luckily changed in AX 2012 and it now reads “To use the relations defined in the AOT Data Dictionary, set to Yes; otherwise No.”
So, below is a full example of linking two datasources with an explicit relation, from code. Note this code works in AX 2009 and AX 2012 both (in AX 2012 you wouldn’t necessarily need the semi-colon separating the declaration).
static void QueryExample(Args _args)
{
Query query;
QueryBuildDatasource datasource;
;
query = new Query();
// Add SalesTable main datasource
datasource = query.addDataSource(tableNum(SalesTable));
// Add child datasource "SalesLine" to previously created DS
datasource = datasource.addDataSource(tableNum(SalesLine));
// Set the join mode
datasource.joinMode(JoinMode::InnerJoin);
// Indicate you don't want to use relations automatically
datasource.relations(false);
// Add link between parent field and child field
datasource.addLink(fieldNum(SalesTable, SalesId),
fieldNum(SalesLine, SalesId));
info(query.xml());
}
</code>
Note how at the end I put the XML representation of the query in the infolog. I have found this to be helpful when troubleshooting issues with query objects, since you can see the actual definition and result of your code:
Oct 13, 2011 - New Whitepaper: AX 2012 Report Programming Model
Filed under: #daxmusings #bizappsThis one is important enough to do a quick blog post on it. Microsoft has just released a new whitepaper on the AX 2012 report programming model. An official manual on reporting is still in the works at Microsoft, but this will give everyone who wants to create SQL reports in AX 2012 a head start.
It talks about using temp tables, best practices and bad practices, and goes through a bunch of examples and the associated code for them.
You can find the download here. As usual, this has been added to my list of AX 2012 Developer Resources.
Oct 11, 2011 - Forum: Advanced Display Method Querying Joined Datasources
Filed under: #daxmusings #bizappsI thought I’d share this code snippet that I posted on the Dynamics AX Community Forums today. The exact post in question is here. The details of this post apply to Dynamics AX 2009 although I have no reason to suspect the code would not work in AX 2012 as well.
The question was on the InventOnHandItem form. The requirement asks to add a display method on the grid showing values from a table that relates to the ItemID and the inventory dimensions displayed on the form. The trick here is that the InventSum is grouped by InventDim fields. So, your display method will not get an inventdim or inventsum record per se, but a grouped version of those, based on the display settings (the button Dimensions Display which you can find on a lot of forms in AX under the inventory buttons).
To open the screen for testing, go to an item with inventory (Inventory Management - Item Details) and click the “on hand” button. This is the screen we’re talking about. The grid shows mostly fields of the InventSum table, although the dimensions are showing from the InventDim table. So we’ll add a display method on the InventSum datasource and we’ll perform a new query in the display method, querying InventSum so that we can compare the result with a field already on the form.
So first, since this is to be added as a form datasource display method, and used on a grid, we need the InventSum record passed in as a parameter to the display method. Next, we need to get the dimension field values from the inventdim record to be used in a new join. Since this display method is on the InventSum, we need to get the joined inventDim record, which we can get by calling “joinChild” on the inventSum buffer.
display Qty AvailPhysical(InventSum _inventSum)
{
InventDim joinDim, dimValues;
InventDimParm dimParm;
InventSum localSum;
dimValues.data(_inventSum.joinChild());
dimParm.initFromInventDim(dimValues);
select sum(AvailPhysical) from localSum where localSum.ItemId == _inventSum.ItemId
#InventDimExistsJoin(localSum.InventDimId, joinDim, dimValues, dimParm);
return localSum.AvailPhysical;
}
</code>
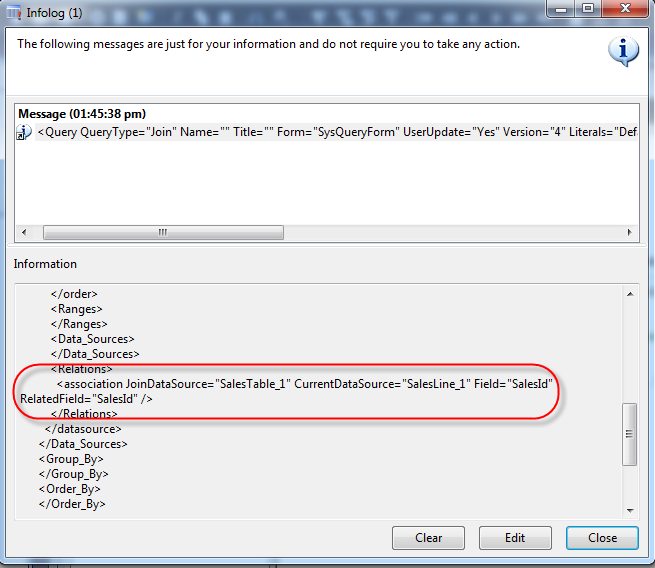
As you can see when I test this, with all dimensions enabled I see my new columns matches the existing column:
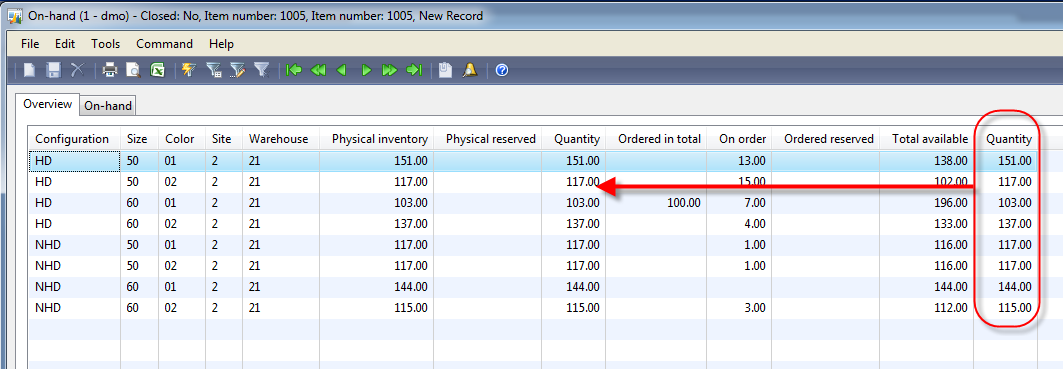
And when I turn off all dimension display except for site and warehouse, the display method is still correct:
So the gotcha and somewhat undocumented feature here is really that we need to get the InventDim out of the _inventSum passed in (using joinChild), since we need the exactly related record, not the currently select grid record we can get from the InventDim datasource on the form.
Two more comments:
Methods such as these could turn out to be performance problems, so make sure to cache display methods where possible. Best practice check will tell you this as well, but you could have some security issues here, make sure to check security for any tables you are selecting on, and document the BP deviation!
Oct 6, 2011 - Valid Time State/Date Effective Framework - Part2
Filed under: #daxmusings #bizappsIn the Part 1 of this article, we went through creating a new table with a valid time state key. You saw how it protects from date overlap and closes gaps automatically. In this article, we’ll see how easy it is to query the table to retrieve the valid record for a given time-frame.
First thing to know is that, AX will by default, without any special keywords, only select the records valid for the current time. So, if we select for our RateID of “DaxMusings” which we created records for in the previous article, we expect to only see one record returned. And that is what happens:
static void ValidTimeStateTest(Args _args)
{
RateTable rateTable;
while select rateTable
where rateTable.RateID == 'DAXMusings'
{
info(strFmt("%1: %2 - %3",
rateTable.RateID,
rateTable.ValidFrom,
rateTable.ValidTo));
}
}
</code>
Your infolog should only output 1 record, regardless of how many records you have in your table. Basically, the system attaches the date ranges with today’s date to the where clause of your query automatically.
So how do we query for a different date than today? Using the ValidTimeState keyword:
static void ValidTimeStateTest(Args _args)
{
RateTable rateTable;
date rateDate = systemDateGet() + 1;
while select validTimeState(rateDate) rateTable
where rateTable.RateID == 'DAXMusings'
{
info(strFmt("%1: %2 - %3",
rateTable.RateID,
rateTable.ValidFrom,
rateTable.ValidTo));
}
}
</code>
This will still only give you 1 result in the infolog. There is one way to get multiple records from this query, and that is by quering for a date range. In our example from yesterday, we added a rate for today and one for tomorrow. So if we query for a date range between today and tomorrow, we should get both records, as such:
static void ValidTimeStateTest(Args _args)
{
RateTable rateTable;
date fromDate = systemDateGet(), toDate = systemDateGet() + 1;
while select validTimeState(fromDate, toDate) rateTable
where rateTable.RateID == 'DAXMusings'
{
info(strFmt("%1: %2 - %3",
rateTable.RateID,
rateTable.ValidFrom,
rateTable.ValidTo));
}
}
</code>
In these examples we’ve been using the Date field type (property on table - see previous article). The same statements will work for the UTCDateTime type, the compiler will check at compile time that the type you’re using for the validTimeSate keyword matches the setting on the table. Note that for UTCDateTime, AX will take into account the timezone of the currently logged in user.
All of these features are available in the query objects as well. By default, the query will behave the same way in that it will automatically filter on the valid time state of today’s date. Same as with the select statement, you can override this behavior with an as-of date or a date range, by setting the options on the query object:
query.ValidTimeStateAsOfDate(rateDate) query.ValidTimeStateDateRange(fromDate, toDate)
</code>
There are similar methods for UTCDateTime type:
query.ValidTimeStateAsOfDatetime(rateDate) query.ValidTimeStateDateTimeRange(fromDate, toDate)
</code>
So to re-write the job from earlier to use the query and queryRun objects, your code should look something like this:
static void ValidTimeStateTest(Args _args)
{
Query query;
QueryRun queryRun;
RateTable rateTable;
date fromDate = systemDateGet(), toDate = systemDateGet() + 1;
query = new Query();
query.addDataSource(tableNum(RateTable)).addRange(fieldNum(RateTable, RateID)).value(queryValue('DAXMusings'));
query.validTimeStateDateRange(fromDate, toDate);
queryRun = new QueryRun(query);
if(queryRun.prompt())
{
while(queryRun.next())
{
rateTable = queryRun.getNo(1);
info(strFmt("%1: %2 - %3",
rateTable.RateID,
rateTable.ValidFrom,
rateTable.ValidTo));
}
}
}
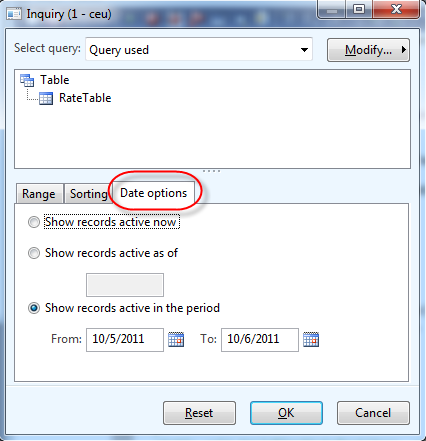
</code> The query dialog that now comes up, will automatically have an extra tab after Range and Sorting, called “Date Options”.
static void ValidTimeStateTest(Args _args)
{
Query query;
QueryRun queryRun;
RateTable rateTable;
date rateDate = systemDateGet();
query = new Query();
query.addDataSource(tableNum(RateTable)).addRange(fieldNum(RateTable, RateID)).value(queryValue('DAXMusings'));
query.validTimeStateAsOfDate(rateDate);
queryRun = new QueryRun(query);
if(queryRun.prompt())
{
while(queryRun.next())
{
rateTable = queryRun.getNo(1);
info(strFmt("%1: %2 - %3",
rateTable.RateID,
rateTable.ValidFrom,
rateTable.ValidTo));
}
}
}
So notice how the query dialog shows both option (as-of as well as date range) so you can flip between the two, you basically provide a "default" in your query object (just like ranges, sorts etc).
That's it for querying. Next article, we'll look at UI (Forms) and how they behave with the date effective framework.
Oct 5, 2011 - Valid Time State/Date Effective Framework - Part 1
Filed under: #daxmusings #bizappsAX 2012 features a new framework called the date effective framework, or valid time state tables. There are many easy examples of date effective data. The easy example is some sort of rate table, where rates become effective and expire at certain times. Other examples could be bills of material or revisions of items that become effective or expire at certain dates. In previous versions of AX, it was up to the developer to implement the logic for querying and validating the date ranges. AX 2012’s date effective framework takes care of the ground work for you. In this article, we’ll walk through the setup, and show you the automatic functionality that comes with it.
Date effective comes in two flavors. One uses regular date fields, the other UtcDateTime data type. Obviously, the UtcDateTime gives you more granularity to the second (and the nice timezone support that comes with UtcDatetime). For this example, we’ll just stick with an easy example using regular dates.
First, we create a new table and we’ll call it RateTable. We’ll give the table a RateID field which identifies the different rates, and a price for each rate.
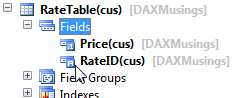
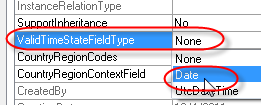
On the table’s properties, we’ll set the ValidTimeStateFieldType to “Date”. This will automatically create two new date fields called “ValidFrom” and “ValidTo”.
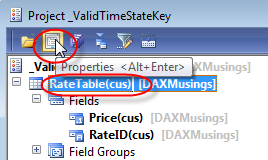
Next, we’ll add an index on the table, containing our RateID identifier and the two date fields. The index needs to be unique, and set as an alternate key.
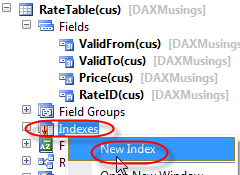
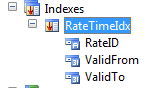
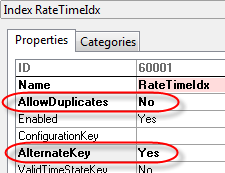
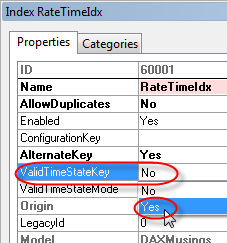
On the index’ property sheet, we’ll set ValidTimeStateKey to “Yes” and ValidTimeStateMode to “NoGap” (should default to NoGap when you set timestatekey to YES). The NoGap value tells the framework we do not allow gaps in the date ranges. For example, for the same RateID, NoGap will not allow one record January 1 to February 1 and a second record of March 1 to April 1, since there would be a gap between February 1 and March 1. We can easily test this once our table is set up.
That is pretty much it. Let’s open the table browser by right-clicking and selecting “Open”. Create a new record by hitting CTRL+N on your keyboard. Notice how the record defaults to ValidFrom with today’s date, and ValidTo set to “never” (if you put your cursor on the field, you’ll notice how the “never” value is actually “12/31/2154”). Give it a RateID of “DAXMusings” (yeah!) and save the record (CTRL+S).
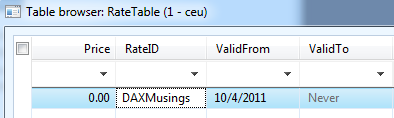
Now, if you create another new record (CTRL+N), it will again default in the same date values. If you enter the RateID “DAXMusings” again and try to save the record (CTRL+S), you will get the error “Insert not supported with the values specified for ‘Effective’ and ‘Expiration’. New record overlaps with multiple existing records”.

So, it obviously doesn’t allow this overlap of the same dates. So, change the ValidFrom field to TOMORROW’s date, and save the record (CTRL+S).
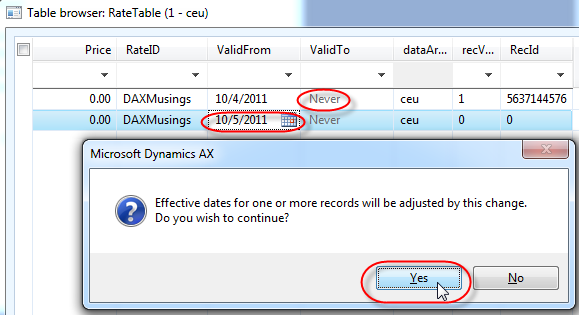
If you click yes, you will notice your previously created record will be updated so that its ValidTo date will be changed from never to a date that connects to your new record (if you follow the example, your first record should now contain today’s date in both ValidFrom and ValidTo fields).
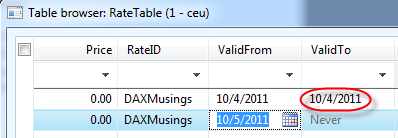
That was pretty easy. Stay tuned, we’ll look at how to query this table next.
Sep 28, 2011 - Query and New Related Objects in AX 2012
Filed under: #daxmusings #bizappsWith AX 2012, some new features were added for queries. For those of you who have access to the DEV manuals, one feature is lightly explained in DEV3, the other is absent in the current development manuals. So, time for a blog post!
Before we begin, I have to point out that there is a slightly annoying trend you will notice. One, the shift away from object IDs and to installation specific IDs. It seems that some new classes in AX 2012 now use element names (classstr, tablestr, etc) instead of tablenum, classnum etc. This is a good thing, however, for objects such as queries, it is annoying that the new classes are not consistent in the use of element identification (old classes use the ID, new classes the string). Secondly, I’m not a fan of the Query classes having “build” in their names, but again, now there’s new classes without “build” in the names, and old classes with “build”. Very inconsistent and annoying. You’ll see what I mean.
So, first new feature, which is touched upon in the DEV3 manual, is the “Filter” object, QueryFilter (not QueryBuildFilter as you may expect). This is a new counterpart to QueryBuildRange. The manual states it is used for outer joins, and filters the data “at a later stage”. Unfortunate choice of words, and not very clear. To understand what’s going on here, you need to understand what happens underneath the covers on the SQL level.
Let’s look at the following scenario. We have a customer table, CustTable, and a sales order table, SalesTable, which has a foreign key relationship to the CustTable based on CustAccount. Let’s say we want to retrieve a list of customers, and optionally any sales orders associated with each customer. To accomplish this, one would use an outer join. In SQL, this would translate as follows:
SELECT * FROM CUSTTABLE
OUTER JOIN SALESTABLE ON SALESTABLE.CUSTACCOUNT = CUSTTABLE.ACCOUNTNUM
</code>
So far so good. Now let’s say we want to show all customers, and show all sales orders associated with each customer, but ONLY the orders with currency EUR… In SQL, this gives us TWO options:
SELECT * FROM CUSTTABLE
OUTER JOIN SALESTABLE ON SALESTABLE.CUSTACCOUNT = CUSTTABLE.ACCOUNTNUM
AND SALESTABLE.CURRENCYCODE = 'EUR'
</code>
or
SELECT * FROM CUSTTABLE
OUTER JOIN SALESTABLE ON SALESTABLE.CUSTACCOUNT = CUSTTABLE.ACCOUNTNUM
WHERE SALESTABLE.CURRENCYCODE = 'EUR'
</code> So what’s the difference? In the first option, we use AND, which means the currencycode is part of the JOIN ON statement filtering the SALESTABLE. In the second option, using the WHERE keyword, the currencycode is part of the query’s selection criteria… so what’s the difference? If we filter the SALESTABLE using the ON clause, the CUSTTABLE will still show up, even if no SALESTABLEs with currency EUR exist, and it will just filter the SALESTABLE records. However, using a WHERE clause, we filter the complete resultset, which means no CUSTTABLE will be returned if there are no SALESTABLE records exist with EUR as the currency.
That is exactly the difference between QueryBuildRange and QueryFilter when used on an outer join. The QueryBuildRange will go in the ON clause, whereas QueryFilter will go in the WHERE clause. The following job illustrates this, feel free to uncomment the range and comment the filter, and vice versa, and test the results for yourself.
static void QueryRangeFilter(Args _args)
{
Query query;
QueryBuildDataSource datasource;
QueryBuildRange range;
QueryFilter filter;
QueryRun queryRun;
int counter = 0, totalCounter = 0;
query = new Query();
datasource = query.addDataSource(tableNum(CustTable));
datasource = datasource.addDataSource(tableNum(SalesTable));
datasource.joinMode(JoinMode::OuterJoin);
datasource.relations(true);
datasource.addLink(fieldNum(CustTable, AccountNum),
fieldNum(SalesTable, CustAccount));
filter = query.addQueryFilter(datasource,
fieldStr(SalesTable, CurrencyCode));
filter.value(SysQuery::value('EUR'));
//range = datasource.addRange(fieldNum(SalesTable, CurrencyCode));
//range.value(SysQuery::value('EUR'));
queryRun = new QueryRun(query);
while (queryRun.next())
{
totalCounter++;
if (queryRun.changed(tableNum(CustTable)))
counter++;
}
info(strFmt("Customer Counter: %1", counter));
info(strFmt("Total result Counter: %1", totalCounter));
}
</code> So, I can hear you thinking “Why is this useful? I could just use an inner join!”. Good catch! One of the main reasons this was introduced is for the user interface. Some screens use outer joins, which works fine. However, when a user filters on fields on the form, the result may not be what that user expects. With a queryBuildRange (as in AX 2009), the query would only filter the joined datasource. So now some fields are showing as empty and read-only (because there is no actual record since it was filtered), but some fields are still showing up (the parent datasource). In this situation, using QueryFilter makes sense. And in fact, AX by default now uses QueryFilter on Forms for any filters a user adds.
Next, the feature that is not mentioned in the DEV books: QueryHavingFilter. For those of you familiar with SQL statements, you are probably aware of the HAVING statement.
Consider the following scenario. The CUSTTABLE table has a field called CUSTGROUP, indicating the customer group the customer belongs to. We would like to get a list of all customer groups that have less than 4 customers in them.
Traditionally, in AX queries, we can group by the CUSTGROUP field, COUNT the RecIds. However, there was no way to filter on that counted RecId field. However, in SQL, the having statement gives you that ability:
SELECT CUSTGROUP, COUNT(*) FROM CUSTTABLE GROUP BY CUSTGROUP HAVING COUNT(*) < 4
</code>In AX you can count, group by, but you’ll need to loop over the results and check the counter manually if you want to filter values out. So, in AX 2012, a new query class was added: QueryHavingFilter, that lets you do just that: <pre>static void QueryHaving(Args _args)
{
Query query;
QueryBuildDataSource datasource;
QueryBuildRange range;
QueryHavingFilter havingFilter;
QueryRun queryRun;
int counter = 0, totalCounter = 0;
CustTable custTable;
query = new Query();
datasource = query.addDataSource(tableNum(CustTable));
datasource.addSelectionField(fieldNum(CustTable, RecId),
SelectionField::Count);
datasource.orderMode(OrderMode::GroupBy);
datasource.addGroupByField(fieldNum(CustTable, CustGroup));
havingFilter = query.addHavingFilter(datasource, fieldStr(custTable, RecId),
AggregateFunction::Count);
havingFilter.value('<4');
queryRun = new QueryRun(query);
while (queryRun.next())
{
custTable = queryRun.getNo(1);
info(strFmt("Group %1: %2", custTable.CustGroup, custTable.RecId));
} }
</pre></code> Note that in this code example, I added a selection field on RecId and used SelectionField::Count. This is not necessary for the having filter to work, the only reason it is in the code example is to be able to show it in the infolog (ie to have the count value available). So it is independent of the HavingFilter!
Unfortunately, the HAVING statement is not yet added to the inline SQL statements of X++. So currently the only way to use this feature is by using query objects.
Sep 27, 2011 - AX 2012 Testing Best Practices
Filed under: #daxmusings #bizappsDave Froslie just announced on his blog that the whitepaper “Testing best practices for AX 2012” is now available for download on Microsoft’s download center.
It is a good read about ALM (Appliction Lifecycle Management) for AX code both in X++ and Visual Studio, and some guidelines and thoughts on testing, unit testing, gathering requirements, peer reviews, etc.
I’ve added the whitepaper download to the ALM/TFS page. I will start posting more new AX2012 content soon, including TFS articles. It’s overdue. There has been the multi-developer single AOS whitepaper, which I thought was a little disappointing, so I’ll make sure to give my thoughts and suggestions on those matters.
Sep 22, 2011 - AX 2012: Multiple Instances of Reporting Services on the same server
Filed under: #daxmusings #bizappsOk, this was a huge deal in AX 2009 in my opinion. During the TAP program of AX 2012, a whitepaper was released on how to do this, but we’ve had to wait until now for Microsoft to make it public. So, yes, it is now possible to have several instances of SQL Reporting running on the same box, connecting to different AOSes. Note that you do need a separate instance of SQL reporting (not one instance connecting to different AOSes), but even that was not possible with AX 2009.
You can find the information on technet at http://technet.microsoft.com/en-us/library/hh389760.aspx.
(Source: EMEADaxSupport blog)
Sep 21, 2011 - Deploying your AX 2012 Code
Filed under: #daxmusings #bizappsYesterday I talked about deploying .NET assemblies, how they get automatically deployed for any Visual Studio projects you have. At the end, I talked briefly about X++ code and the CIL assemblies. I will take that a bit further today. If you haven’t read the Microsoft whitepaper on “Deploying Customization Across Microsoft Dynamics AX 2012 Environments” I suggest you take a look at that, it’s a good read.
We had a gathering with some other MCTs at Microsoft’s offices in Fargo, and we had a big discussion around deploying the customizations, and the “high availability” scenario where you want to deploy code, but avoid too much downtime. But let’s not get ahead of ourselves too quickly.
[Editing note: I admit, I like to rant. Please bear with me, I promise it will get interesting further down :-)]
I made this statement to one of our clients a few months ago, and I’d like to share it with you: moving XPOs is barbaric. Yes, barbaric. As AX developers, administrators, implementers and customers we need to move on. Yes, moving XPOs has some benefits, but they are all benefits to circumvent proper procedure. The benefit of moving one piece of code? That’s introducing risk and circumventing proper code release management (branching and merging for the version control aficionados). The benefit of no downtime? That is bad practice, what about users that have cached versions of your code running in their sessions? Not to mention data dictionary changes. The benefit of not having to recompile the whole codebase? Talk about bad practice again, and all the possible issues that come out of that. Sure, you say, but I am smart and I know what I can move without risk. Famous last words. And that’s not a reason to circumvent proper code release procedures anyway. Here’s my take:
1) Code should be released in binary form. For AX 2009 that means, layers. In AX 2012, we have models. Have you ever received a .cpp or .cs code file from Microsoft containing a patch for Windows or Office? Didn’t think so.
2) Released code should be guaranteed to be the same as the tested code (I’m sure your auditors will agree) When importing an XPO there is an overwrite and/or merge step that happens. This is prone to user error. Also, who is importing the XPO? If there is no chance of doing anything wrong or different, can’t you just have a user do it? Yeah, didn’t think so either.
3) You should schedule downtime to install code updates Sure, AX doesn’t mind a code update while that code is still running. A binary update? Not so much, you need to restart the AOS. Remember Windows asking to restart the system after an update was installed? Yes, there’s a good reason for that, to replace stuff that’s in use.
I can keep going for a while, but those are my main points. So, back to AX 2012. I will relate this to the points above.
1) Models are binary files. The .AxModel files are technically assemblies, if you open them up in Reflector or ILSpy you won’t see too much though, it contains the model manifest (XML) as a resource, and a BinaryModel resource. The model is a subset of a specific layer, so it’s a more granular way to move code than moving layers was in AX 2009. But, just like in AX 2009, since this is not the full application, after installing the model one should compile the application. An additional reason to do so in AX 2012 is the fact that the model also contains compiled X++ p-code. Any references to other classes, fields, etc gets compiled into IDs. In 2012, those IDs are installation-specific. That means your code using field ABC may have been compiled to use fieldID 1, but perhaps in the new environment you’re importing this model into, the field ABC is really fieldID 2. So now your code, when run, will reference the wrong field (you can actually test this, it’s freaky). So, compiling is a necessity. Also think of situations where your model modifies a base class. The whole application needs to be recompiled to make sure all derived classes get your update compiled into them (yes, you can do compile forward, assuming the person installing the model is aware of what is actually in the model). You can replace an existing model. This avoids the typical XPO issue where you need to import with “delete elements” enabled. Which you can’t always do since you may not want to remove other fields that are not in your XPO, but belong to another project. The model knows what it contained previously, and what it contains now, and will only delete the specific changes for your model. One thing to remember is that you should never uninstall the old model and install the new one. This will likely cause havoc in your object IDs, which means tables will get dropped and recreated rather than updated!
2) Obviously by exporting the model from an existing environment where you tested, the code will be the same. Same confidence as moving layers in previous versions of AX. Another method is moving the code using branch merging in a source environment, and creating a binary build out of that. In this case you are branching a known and tested set of code, and have full traceability of the code as it progresses through your testing and release processes.
3) Ok, this is all great, but… compiling in AX 2012 takes a LONG time compared to AX 2009. And then we need to generate the CIL as well (which doesn’t take that long in my experience)! So you catch my drift on the whole binary deployment, you see what I mean with matching released code to tested code… and starting the AOS is one thing, but having to recompile and wait for that to complete? That could be some serious downtime!
Enter.. the model store! Think about this. The model store today, is what the APPL directory used to be in previous releases. It contains EVERYTHING. The layers, which contain the code, the labels, etc. So, it contains the compiled code as well. In fact, the model store even contains the generated compiled IL code. So, going back to the “Deploying Customization Across Microsoft Dynamics AX 2012 Environments” whitepaper. It has this section called “import to the target system”. To avoid downtime, you should have a code-copy of your production environment ready, where you can replace models, do whatever you need, and then compile the application and generate the CIL for X++. This is what the whitepaper means with the “source system”. When that system is fully prepped, you can export the FULL model store. Again, this contains source code, compiled code, CIL and even your VS projects’ built assemblies! To further avoid down time, you can import the model store into production (the “target” system in the whitepaper) using a different schema. This basically lets you “import” the modelstore without disturbing the production system. Then, whenever you are ready, you can stop the AOS, and apply your temporary schema, effectively replacing the code in production with the code you built. The only thing you have to do still, after starting the AOS, is synchronize the database (and deploy web and reporting artifacts). And of course, clean up the model store’s old schema.
So, when you start up the AOS, it will recognize the changed CIL in the modelstore, and download it to its bin\vsassemblies directory (see my previous article).
Now that’s what I call high availability. So… no more reason to not move code in binary form! No more barbarism.
Sep 20, 2011 - AX 2012 .NET Assembly Deployment
Filed under: #daxmusings #bizappsCompared to AX 2009, assemblies in AX 2012 work a bit differently. One of the obvious differences is the introduction of visual studio projects. However, deploying the assemblies works differently, in our favor (of course!). There are a few things we need to keep in mind though, and definitely a few bad habits from AX 2009 to get rid of!
AX 2012 improves assembly deployment and referencing. For the client side of things, this means the assemblies no longer need to be copied to the client/bin folder. The development manuals for AX 2012 INCORRECTLY state that the assembly automatically gets downloaded by the client to the client bin folder. This is incorrect. The assemblies get downloaded to %USERPROFILE%\AppData\Local\Microsoft\Dynamics AX\VSAssemblies . The %USERPROFILE% by default on Windows 7 should be C:\Users\username so if your user name is DAXMUSINGS, the assemblies will be in C:\Users\DAXMUSINGS\AppData\Local\Microsoft\Dynamics AX\VSAssemblies . Make a correction in your 2012 development manual! Since the assemblies are kept by user, that means in a multi-user environment such as terminal services or Citrix, there is no need for all users to log out (ie all client executables closed so no more assembly files are in use) before a new assembly can be deployed. First, you don’t have to deploy, AX does it for you. Secondly, any time a user restarts AX, it will download the new assemblies where and if needed. It also means different users could have different versions of your code in use. This could happen traditionally with X++ as well, so it’s always a good idea to schedule downtime to deploy new code, managed or otherwise.
So, when you build a Visual Studio project and click “deploy” in Visual Studio (or, in fact, if you just build the project and then restart your AX client), your AX client will, the next time it needs the assembly, detect a newer version of the assembly and copy it into the VSAssemblies directory. Also note that you can in fact build the project from the AOT. When you right-click/compile on a Visual Studio project, AX builds the project and thus a new assembly.
What happens on the server side? A similar thing, except here the assemblies are deployed to the server bin/VSAssemblies . By default, the AOS runs in 1 AppDomain which means you need to restart the AOS server to get the new assembly. But, in a developer environment you may be recompiling your assembly a lot, so to avoid having to restart your AOS constantly, hotswapping was enabled for the AOS. Check this MSDN page for more information. You should definitely never enable hotswapping in a production environment!
So, for anyone who has dealt with VS projects in previous versions, please don’t copy assembly DLLs into your BIN directories. It will deploy automatically, refresh automatically, and load automatically. Also remember you don’t have to explicitly add your Visual Studio’s project as a reference in the AOT. The fact that it is an AOT VS project makes it available as an implicit reference anywhere in X++ . If you missed it previously, you may want to check out the managed code series for a look on how to create managed code projects.
Then there is the X++ compiled to IL. Those are assemblies too! Well, X++ is kept in the model store now. This includes the X++ source, the X++ p-code, and the X++ compiled IL. These compiled pieces are versioned, and the AOS will download newer versions of the X++ assemblies to it’s server bin/XppIL folder, including the PDB files so you can debug that X++ running in the CLR using Visual Studio.
Blog Links

Blog Post Collections
- The LLM Blogs
- Dynamics 365 (AX7) Dev Resources
- Dynamics AX 2012 Dev Resources
- Dynamics AX 2012 ALM/TFS
Recent Posts
-
GPT4-o1 Test Results
Read more... -
Small Language Models
Read more... -
Orchestration and Function Calling
Read more... -
From Text Prediction to Action
Read more... -
The Killer App
Read more...